Re-posted from: http://www.stochasticlifestyle.com/6-months-differentialequations-jl-going/
So around 6 months ago, DifferentialEquations.jl was first registered. It was at first made to be a library which can solve “some” types of differential equations, and that “some” didn’t even include ordinary differential equations. The focus was mostly fast algorithms for stochastic differential equations and partial differential equations.
Needless to say, Julia makes you too productive. Ambitions grew. By the first release announcement, much had already changed. Not only were there ordinary differential equation solvers, there were many. But the key difference was a change in focus. Instead of just looking to give a production-quality library of fast methods, a major goal of DifferentialEquations.jl became to unify the various existing packages of Julia to give one user-friendly interface.
Since that release announcement, we have enormous progress. At this point, I believe we have both the most expansive and flexible differential equation library to date. I would like to take this time to explain the overarching design, where we are, and what you can expect to see in the near future.
(Note before we get started: if you like what you see, please star the DifferentialEquations.jl repository. I hope to use this to show interest in the package so that one day we can secure funding. Thank you for your support!)
JuliaDiffEq Structure
If you take a look at the source for DifferentialEquations.jl, you will notice that almost all of the code has gone. What has happened?
The core idea behind this change is explained in another blog post on modular interfaces for scientific computing in Julia. The key idea is that we built an interface which is “package-independent”, meaning that the same lines of code can call solvers from different packages. There are many advantages to this which will come up later in the section which talks about the “addon packages”, but one organizational advantage is that it lets us split up the repositories as needed. The core differential equation solvers from DifferentialEquations.jl reside in OrdinaryDiffEq.jl, StochasticDiffEq.jl, etc. (you can see more at our webpage). Packages like Sundials.jl, ODEInterface.jl, ODE.jl, etc. all have bindings to this same interface, making them all work similarly.
One interesting thing about this setup is that you are no longer forced to contribute to these packages in order to contribute to the ecosystem. If you are a developer or a researcher in the field, you can develop your own package with your own license which has a common interface binding, and you will get the advantages of the common interface without any problems. This may be necessary for some researchers, and so we encourage you to join in and contribute as you please.
The Common Interface
Let me then take some time to show you what this common interface looks like. To really get a sense, I would recommend checking out the tutorials in the documentation and the extra Jupyter notebook tutorials in DiffEqTutorials.jl. The idea is that solving differential equations always has 3 steps:
- Defining a problem.
- Solving the problem.
- Analyzing the solution.
Defining a problem
What we created was a generic type-structure for which dispatching handles the details. For defining an ODE problem, one specifies the function for the ODE, the initial condition, and the timespan that the problem is to be solved on. The ODE

with an initial condition  and and timespan
and and timespan  is then written as:
is then written as:
prob = ODEProblem(f,u0,(t0,tf))
There are many different problem types for different types of differential equations. Currently we have types (and solvers) for ordinary differential equations, stochastic differential equations, differential algebraic equations, and some partial differential equations. Later in the post I will explain how this is growing.
Solving the problem
To solve the problem, the common solve command is:
sol = solve(prob,alg;kwargs...)
where alg is a type-instance for the algorithm. It is by dispatch on alg that the package is chosen. For example, we can call the 14th-Order Feagin Method from OrdinaryDiffEq.jl via
sol = solve(prob,Feagin14();kwargs...)
We can call the BDF method from Sundials.jl via
sol = solve(prob,CVODE_BDF();kwargs...)
Due to this structure (and the productivity of Julia), we have a ridiculous amount of methods which are available as is seen in the documentation. Later I will show that we do not only have many options, but these options tend to be very fast, often benchmarking as faster than classic FORTRAN codes. Thus one can choose the right method for the problem, and efficient solve it.
Notice I put in the trailing “kwargs…”. There are many keyword arguments that one is able to pass to this solve command. The “Common Solver Options” are documented at this page. Currently, all of these options are supported by the OrdinaryDiffEq.jl methods, while there is general support for large parts of this for the other methods. This support will increase overtime, and I hope to include a table which shows what is supported where.
Analyzing the solution
Once you have this solution type, what does it do? The details are explained in this page of the manual, but I would like to highlight some important features.
First of all, the solution acts as an array. For the solution at the ith timestep, you just treat it as an array:
sol[i]
You can also get the ith timepoint out:
sol.t[i]
Additionally, the solution lets you grab individual components. For example, the jth component at the ith timepoint is found by:
sol[i,j]
These overloads are necessary since the underlying data structure can actually be a more complicated vector (some examples explained later), but this lets you treat it in a simple manner.
Also, by default many solvers have the option “dense=true”. What this means is that the solution has a dense (continuous) output, which is overloaded on to the solver. This look like:
sol(t)
which gives the solution at time t. This continuous version of the solution can be turned off using “dense=false” (to get better performance), but in many cases it’s very nice to have!
Not only that, but there are some standard analysis functions available on the solution type as well. I encourage you to walk through the tutorial and see for yourself. Included are things like plot recipes for easy plotting with Plots.jl:
plot(sol)
Now let me describe what is available with this interface.
Ecosystem-Wide Development Tools and Benchmarks
Since all of the solutions act the same, it’s easy to create tools which build off of them. One fundamental toolset are those included in DiffEqDevTools.jl. DiffEqDevTools.jl includes a bunch of functions for things like convergence testing and benchmarking. This not only means that all of the methods have convergence tests associated with them to ensure accuracy and correctness, but also that we have ecosystem-wide benchmarks to know the performance of different methods! These benchmarks can be found at DiffEqBenchmarks.jl and will be referenced throughout this post.
Very Efficient Nonstiff ODE Solvers
The benchmarks show that the OrdinaryDiffEq.jl methods achieve phenomenal performance. While in many cases other libraries resort to the classic dopri5 and dop853 methods due to Hairer, in our ecosystem have these methods available via the ODEInterface.jl glue package ODEInterfaceDiffEq.jl and so these can be directly called from the common interface. From the benchmarks on non-stiff problems you can see that the OrdinaryDiffEq.jl methods are much more efficient than these classic codes when one is looking for the highest performance. This is even the case for DP5() and DP8() which have the same exact timestepping behavior as dopri5() and dop853() respectively, showing that these implementations are top notch, if not the best available.

These are the benchmarks on the implementations of the Dormand-Prince 4/5 methods. Also included is a newer method, the Tsitorous 4/5 method, which is now the default non-stiff method in DifferentialEquations.jl since our research has shown that it is more efficient than the classical methods (on most standard problems).
A Wide Array of Stiff ODE Solvers
There is also a wide array of stiff ODE solvers which are available. BDF methods can be found from Sundials.jl, Radau methods can be found from ODEInterface.jl, and a well-optimized 2nd-Order Rosenbrock method can be found in OrdinaryDiffEq.jl. One goal in the near future will be to implement higher order Rosenbrock methods in this fashion, since it will be necessary to get better performance, as shown in the benchmarks. However, the Sundials and ODEInterface methods, being that they use FORTRAN interop, are restricted to equations on Float64, while OrdinaryDiffEq.jl’s methods support many more types. This allows one to choose the best method for the job.
Wrappers for many classic libraries
Many of the classic libraries people are familiar with are available from the common interface, including:
- CVODE
- LSODA
- The Hairer methods
and differential algebraic equation methods including
- IDA (Sundials)
- DASKR
Native Julia Differential Algebraic Equation Methods
DASSL.jl is available on the common interface and provides a method to solve differential algebraic equations using a variable-timestep BDF method. This allows one to support some Julia-based types like arbitrary-precision numbers which are not possible with the wrapped libraries.
Extensive Support for Julia-based Types in OrdinaryDiffEq.jl
Speaking of support for types, what is supported? From testing we know that the following work with OrdinaryDiffEq.jl:
- Arbitrary precision arithmetic via BigFloats, ArbFloats, DecFP
- Numbers with units from Unitful.jl
- N-dimensional arrays
- Complex numbers (the nonstiff solvers)
- “Very arbitrary arrays”
Your numbers can be ArbFloats of 200-bit precision in 3-dimensional tensors with units (i.e. “these numbers are in Newtons”), and the solver will ensure that the dimensional constraints are satisfied, and at every timestep give you a 3-dimensional tensor with 200-bit ArbFloats. The types are declared to match the initial conditions: if you start with u0 having BigFloats, you will be guaranteed to have BigFloat solutions. Also, the types for time are determined by the types for the times in the solution interval (t0,tf). Therefore can have the types for time be different than the types for the solution (say, turn off adaptive timestepping and do fixed timestepping with rational numbers or integers).
Also, by “very arbitrary arrays” I mean, any type which has a linear index can be used. One example which recently came up in this thread involves solving a hybrid-dynamical system which has some continuous variables and some discrete variables. You can make a type which has a linear index over the continuous variables and simply throw this into the ODE solver and it will know what to do (and use callbacks for discrete updates). All of the details like adaptive timestepping will simply “just work”.
Thus, I encourage you to see how these methods can work for you. I myself have been developing MultiScaleModels.jl to build multi-scale hybrid differential equations and solve them using the methods available in DifferentialEquations.jl. This shows that heuristic for classic problems which you “cannot use a package for” no longer apply: Julia’s dispatch system allows DifferentialEquations.jl to handle these problems, meaning that there is no need for you to have to ever reinvent the wheel!
Event Handling and Callbacks in OrdinaryDiffEq.jl
OrdinaryDiffEq.jl already has extensive support for callback functions and event handling. The documentation page describes a lot of what you can do with it. There are many things you can do with this, not just bouncing a ball, but you can also use events to dynamically change the size of the ODE (as demonstrated by the cell population example).
Specification of Extra Functions for Better Performance
If this was any other library, the header would have been “Pass Jacobians for Better Performance”, but DifferentialEquations.jl’s universe goes far beyond that. We named this set of functionality Performance Overloads. An explicit function for a Jacobian is one type of performance overload, but you can pass the solvers many other things. For example, take a look at:
f(Val{:invW},t,u,γ,iW) # Call the explicit inverse Rosenbrock-W function (M - γJ)^(-1)
This seems like an odd definition: it is the analytical function for the equation  for some mass matrix
for some mass matrix  built into the function. The reason why this is so necessary is because Rosenbrock methods have to solve this every step. What this allows the developers to do is write a method which goes like:
built into the function. The reason why this is so necessary is because Rosenbrock methods have to solve this every step. What this allows the developers to do is write a method which goes like:
if has_invW(f) # Use the function provided by the user else # Get the Jacobian # Build the W # Solve the linear system end
Therefore, whereas other libraries would have to use a linear solver to solve the implicit equation at each step, DifferentialEquations.jl allows developers to write this to use the pre-computed inverses and thus get an explicit method for stiff equations! Since the linear solves are the most expensive operation, this can lead to huge speedups in systems where the analytical solution can be computed. But is there a way to get these automatically?
Parameterized Functions and Function Definition Macros
ParameterizedFunctions.jl is a library which solves many problems at one. One question many people have is, how do you provide the model parameters to an ODE solver? While the standard method of “use a closure” is able to work, there are many higher-order analyses which require the ability to explicitly handle parameters. Thus we wanted a way to define functions with explicit parameters.
The way that this is done is via call overloading. The syntax looks like this. We can define the Lotka-Volterra equations with explicit parameters  and
and  via:
via:
type LotkaVolterra <: Function a::Float64 b::Float64 end f = LotkaVolterra(0.0,0.0) (p::LotkaVolterra)(t,u,du) = begin du[1] = p.a * u[1] - p.b * u[1]*u[2] du[2] = -3 * u[2] + u[1]*u[2] end
Now f is a function where f.a and f.b are the parameters in the function. This type of function can then be seamlessly used in the DifferentialEquations.jl solvers, including those which use interop like Sundials.jl.
This is very general syntax which can handle any general function. However, the next question was, is there a way to do this better for the problems that people commonly encounter? Enter the library ParameterizedFunctions.jl. As described in the manual, this library (which is part of DifferentialEquations.jl) includes a macro @ode_def which allows you to define the Lotka-Volterra equation

as follows:
f = @ode_def LotkaVolterraExample begin dx = a*x - b*x*y dy = -c*y + d*x*y end a=>1.5 b=>1.0 c=>3.0 d=1.0
Notice that at the bottom you pass in the parameters. => keeps the parameters explicit, while = passes them in as a constant. Flip back and forth to see that it matches the LaTeX so that way it’s super easy to debug and maintain.
But this macro isn’t just about ease of use: it’s also about performance! What happens silently within this macro is that symbolic calculations occur via SymEngine.jl. The Performance Overloads functions are thus silently symbolically computed, allowing the solvers to then get maximal performance. This gives you an easy way to define a stiff equation of 100 variables in a very intuitive way, yet get a faster solution than you would find with other libraries.
Sensitivity Analysis
Once we have explicit parameters, we can generically implement algorithms which use them. For example, DiffEqSensitivity.jl transforms a ParameterizedFunction into the senstivity equations which are then solved using any ODE solver, outputting both the ODE’s solution and the parameter sensitivities at each timestep. This is described in the manual in more detail. The result is the ability to use whichever differential equation method in the common interface matches your problem to solve the extended ODE and output how sensitive the solution is to the parameters. This is the glory of the common interface: tools can be added to every ODE solver all at once!
In the future we hope to increase the functionality of this library to include functions for computing global and adjoint sensitivities via methods like the Morris method. However, the current setup shows how easy this is to do, and we just need someone to find the time to actually do it!
Parameter Estimation
Not only can we identify parameter sensitivities, we can also estimate model parameters from data. The design of this is described in more detail is explained in the manual. It is contained in the package DiffEqParamEstim.jl. Essentially, you can define a function using the @ode_def macro, and then pair it with any ODE solver and (almost) any optimization method, and together use that to find the optimal parameters.
In the near future, I would like to increase the support of DiffEqParamEstim.jl to include machine learning methods from JuliaML using its Learn.jl. Stay tuned!
Adaptive Timestepping for Stochastic Differential Equations
Adaptive timestepping is something you will not find in other stochastic differential equation libraries. The reason is because it’s quite hard to do correctly and, when finally implemented, can have so much overhead that it does not actually speedup the runtime for most problems.
To counteract this, I developed a new form of adaptive timestepping for stochastic differential equations which focused on both correctness and an algorithm design which allows for fast computations. The result was a timestepping algorithm which is really fast! This paper has been accepted to Discrete and Continuous Dynamical Systems Series B, and where we show that the correctness of the algorithm and its efficiency. We actually had to simplify the test problem so that way we could time the speedup over fixed timestep algorithms, since otherwise they weren’t able to complete in a reasonable time without numerical instability! When simplified, the speedup over all of the tested fixed timestep methods was >12x, and this speedup only increases as the problem gets harder (again, we chose the simplified version only because testing the fixed timestep methods on harder versions wasn’t even computationally viable!).
These methods, Rejection Sampling with Memory (RSwM), are available in DifferentialEquations.jl as part of StochasticDiffEq.jl. It should help speed up your SDE calculations immensely. For more information, see the publication “Adaptive Methods for Stochastic Differential Equations via Natural Embeddings and Rejection Sampling with Memory”.
Easy Multinode Parallelism For Monte Carlo Problems
Also included as part of the stochastic differential equation suite are methods for parallel solving of Monte Carlo problems. The function is called as follows:
monte_carlo_simulation(prob,alg;numMonte=N,kwargs...)
where the extra keyword arguments are passed to the solver, and N is the number of solutions to obtain. If you’ve setup Julia on a multinode job on a cluster, this will parallelize to use every core.
In the near future, I hope to expand this to include a Monte Carlo simulation function for random initial conditions, and allow using this on more problems like ODEs and DAEs.
Smart Defaults
DifferentialEquations.jl also includes a new cool feature for smartly choosing defaults. To use this, you don’t really have to do anything. If you’ve defined a problem, say an ODEProblem, you can just call:
sol = solve(prob;kwargs...)
without passing the algorithm and DifferentialEquations.jl will choose an algorithm for you. Also included is an `alg_hints` parameter with allows you to help the solver choose the right algorithm. So lets say you want to solve a stiff stochastic differential equations, but you do not know much about the algorithms. You can do something like:
sol = solve(prob,alg_hints=[:stiff])
and this will choose a good algorithm for your problem and solve it. This reduces user-burden to only having to know properties of the problem, while allowing us to proliferate the solution methods. More information is found in the Common Solver Options manual page.
Progress Monitoring
Another interesting feature is progress monitoring. OrdinaryDiffEq.jl includes the ability to use Juno’s progressbar. This is done via the keyword arguments like:
sol = solve(prob,progress=true, progress_steps=100)
You can also set a progress message, for which the default is:
ODE_DEFAULT_PROG_MESSAGE(dt,t,u) = "dt="*string(dt)*"\nt="*string(t)*"\nmax u="*string(maximum(abs.(u)))
When you scroll over the progressbar, it will show you how close it is to the final timepoint and use linear extrapolation to estimate the amount of time left to solve the problem.

When you scroll over the top progressbar, it will display the message. Here, it tells us the current dt, t, and the maximum value of u (the independent variable) to give a sanity check that it’s all working.

The keyword argument progress_steps lets you control how often the progress bar updates, so here we choose to do it every 100 steps. This means you can do some very intense sanity checks inside of the progress message, but reduce the number of times that it’s called so that way it doesn’t affect the runtime.
All in all, having this built into the interface should make handling long and difficult problems much easier, I problem that I had when using previous packages.
(Stochastic) Partial Differential Equations
There is rudimentary support for solving some stochastic partial differential equations which includes semilinear Poisson and Heat equations. This is able to be done on a large set of domains using a finite element method as provided by FiniteElementDiffEq.jl. I will say that this library is in need of an update for better efficiency, but it shows how we are expanding into the domain of adding easy-to-define PDE problems, which then create the correct ODEProblem/DAEProblem discretization and which then gets solved using the ODE methods.
Modular Usage
While all of this creates the DifferentialEquations.jl package, the JuliaDiffEq ecosystem is completely modular. If you want to build a library which uses only OrdinaryDiffEq.jl’s methods, you can directly use those solvers without requiring the rest of DifferentialEquations.jl
An Update Blog
Since things are still changing fast, the website for JuliaDiffEq contains a news section which will describe updates to packages in the ecosystem as they occur. To be notified of updates, please subscribe to the RSS feed.
Coming Soon
Let me take a few moments to describe some works in progress. Many of these are past planning stages and have partial implementations. I find some of these very exciting.
Solver Method Customization
The most common reason to not use a differential equation solver library is because you need more customization. However, as described in this blog post, we have developed a design which solves this problem. The advantages huge. Soon you will be able to choose the linear and nonlinear solvers which are employed in the differential equation solving methods. For linear solvers, you will be able to use any method which solves a linear map. This includes direct solvers from Base, iterative solvers from IterativeSolvers.jl, parallel solvers from PETSc.jl, GPU methods from CUSOLVER.jl: it will be possible to even use your own linear solver if you wish. The same will be true for nonlinear solvers. Thus you can choose the internal methods which match the problem to get the most efficiency out.
Specialized Problem Types and Promotions
One interesting setup that we have designed is a hierarchy of types. This is best explained by example. One type of ODE which shows up are “Implicit-Explicit ODEs”, written as:

where  is a “stiff” function and
is a “stiff” function and  is a “nonstiff” function. These types of ODEs with a natural splitting commonly show up in discretizations of partial differential equations. Soon we will allow one to define an IMEXProblem(f,g,u0,tspan) for this type of ODE. Specialized methods such as the ARKODE methods from Sundials will then be able to utilize this form to gain speed advantages.
is a “nonstiff” function. These types of ODEs with a natural splitting commonly show up in discretizations of partial differential equations. Soon we will allow one to define an IMEXProblem(f,g,u0,tspan) for this type of ODE. Specialized methods such as the ARKODE methods from Sundials will then be able to utilize this form to gain speed advantages.
However, lets say you just wanted to use a standard Runge-Kutta method to solve this problem? What we will automatically do via promotion is make

and then behind the scenes the Runge-Kutta method will solve the ODE

Not only that, but we can go further and define

to get the equation

which is a differential algebraic equation solver. This auto-promotion means that any method will be able to solve any problem type which is lower than it.
The advantages are two-fold. For one, it allows developers to write a code to the highest problem available, and automatically have it work on other problem types. For example, the classic Backwards Differentiation Function methods (BDF) which are seen in things like MATLAB’s ode15s are normally written to solve ODEs, but actually can solve DAEs. In fact, DASSL.jl is an implementation of this algorithm. When this promotion structure is completed, DASSL’s BDF method will be a native BDF method not just for solving DAEs, but also ODEs, and there is no specific development required on the part of DASSL.jl. And because Julia’s closures compile to fast functions, all of this will happen with little to no overhead.
In addition to improving developer productivity, it allows developers to specialize methods to problems. The splitting methods for implicit-explicit problems can be tremendously more performant since it reduces the complexity of the implicit part of the equation. However, with our setup we go even further. One common case that shows up in partial differential equations is that one of these equations is linear. For example, in a discretization of the semilinear Heat Equation, we arise at an ODE

where  is a matrix which is the discretization of the LaPlacian. What our ecosystem will allow is for the user to specify that the first function
is a matrix which is the discretization of the LaPlacian. What our ecosystem will allow is for the user to specify that the first function  is a linear function by wrapping it in a LinearMap type from LinearMaps.jl. Then the solvers can use this information like:
is a linear function by wrapping it in a LinearMap type from LinearMaps.jl. Then the solvers can use this information like:
if is_linear(f) # Perform linear solve else # Perform nonlinear solve end
This way, the solvers will be able to achieve even more performance by specializing directly to the problem at hand. In fact, it will allow methods require this type of linearity like Exponential Runge-Kutta methods to be able to be developed for the ecosystem and be very efficient methods when applicable.
In the end, users can just define their ODE by whatever problem type makes sense, and promotion magic will make tons of methods available, and type-checking within the solvers will allow them to specialize directly to every detail of the ODE for as much speed as possible. With DifferentialEquations.jl also choosing smart default methods to solve the problem, the user-burden is decreased and very specialized methods can be used to get maximal efficiency. This is a win for everybody!
Ability to Solve Fun Types from ApproxFun.jl
ApproxFun.jl provides an easy way to do spectral approximations of functions. In many cases, these spectral approximations are very fast and are used to decompose PDEs in space. When paired with timestepping methods, this gives an easy way to solve a vast number of PDEs with really good efficiency.
The link between these two packages is currently found in SpectralTimeStepping.jl. Currently you can fix the basis size for the discretization and use that to solve the PDE with any ODE method in the common interface. However, we are looking to push further. Since OrdinaryDiffEq.jl can handle many different Julia-defined types, we are looking to make it support solving the ApproxFun.jl Fun type directly, which would allow the ODE solver to adapt the size of the spectral basis during the computation. This would tremendously speedup the methods and make it as fast as if you were to specifically design a spectral method to a PDE. We are really close to getting this!
New Methods for Stochastic Differential Equations
I can’t tell you too much about this because these methods will be kept secret until publication, but there are some very computationally-efficient methods for nonstiff and semi-stiff equations which have already been implemented and are being thoroughly tested. Go tell the peer review process to speedup if you want these quicker!
Improved Plot Recipes
There is already an issue open for improving the plot recipes. Essentially what will come out of this will be the ability to automatically draw phase plots and other diagrams from the plot command. This should make using DifferentialEquations.jl even easier than before.
Uncertainty Quantification
One major development in scientific computing has been the development of methods for uncertainty quantification. This allows you to quantify the amount of error that comes from a numerical method. There is already a design for how to use the ODE methods to implement a popular uncertainty quantification algorithm, which would allow you to see a probability distribution for the numerical solution to show the uncertainty in the numerical values. Like the sensitivity analysis and parameter estimation, this can be written in a solver-independent manner so that way it works with any solver on the common interface (which supports callbacks). Coming soon!
Optimal Control
We have in the works for optimal control problem types which will automatically dispatch to PDE solvers and optimization methods. This is a bit off in the distance, but is currently being planned.
Geometric and Symplectic Integrators
A newcomer to the Julia-sphere is GeometricIntegrators.jl. We are currently in the works for attaching this package to the common interface so that way it will be easily accessible. Then, Partitioned ODE and DAE problems will be introduced (with a promotion structure) which will allow users to take advantage of geometric integrators for their physical problems.
Bifurcation Analysis
Soon you will be able to take your ParameterizedFunction and directly generate bifurcation plots from it. This is done by a wrapper to the PyDSTool library via PyDSTool.jl, and a linker from this wrapper to the JuliaDiffEq ecosystem via DiffEqBifurcate.jl. The toolchain already works, but… PyCall has some nasty segfaults. When these segfaults are fixed in PyCall.jl, this functionality will be documented and released.
Models Packages
This is the last coming soon, but definitely not the least. There are already a few “models packages” in existence. What these packages do is provide functionality which makes it easy to define very specialized differential equations which can be solved with the ODE/SDE/DAE solvers. For example, FinancialModels.jl makes it easy to define common equations like Heston stochastic volatility models, which will then convert into the appropriate stochastic differential equation or PDE for use in solver methods. MultiScaleModels.jl allows one to specify a model on multiple scales: a model of proteins, cells, and tissues, all interacting dynamically with discrete and continuous changes, mixing in stochasticity. Also planned is PhysicalModels.jl which will allow you to define ODEs and DAEs just by declaring the Hamiltonian or Legrangian functions. Together, these packages should help show how the functionality of DifferentialEquations.jl reaches far beyond what previous differential equation packages have allowed, and make it easy for users to write very complex simulations (all of course without the loss of performance!).
Conclusion
I hope this has made you excited to use DifferentialEquaitons.jl, and excited to see what comes in the future. To support this development, please star the DifferentialEquations.jl repository. I hope to use these measures of adoption to one day secure funding. In the meantime, if you want to help out, join in on the issues in JuliaDiffEq, or come chat in the JuliaDiffEq Gitter chatroom. We’re always looking for more hands! And to those who have already contributed: thank you as this would not have been possible without each and every one of you.
The post 6 Months of DifferentialEquations.jl: Where We Are and Where We Are Going appeared first on Stochastic Lifestyle.
 denote consumption and
denote consumption and  denote leisure. Consider an agent who wishes to maximize Cobb-Douglas utility over consumption and leisure, that is,
denote leisure. Consider an agent who wishes to maximize Cobb-Douglas utility over consumption and leisure, that is, =")
 .
. is the relative preference for consumption. The budget constraint is given by,
is the relative preference for consumption. The budget constraint is given by,w_i(1-l_i)+\epsilon_i") ,
, is the wage observed in the data,
is the wage observed in the data,  is other income that is not observed in the data, and
is other income that is not observed in the data, and  is the tax rate.
is the tax rate.") subject to the budget constraint. We assume that non-labor income is uncorrelated with the wage offer, so that
subject to the budget constraint. We assume that non-labor income is uncorrelated with the wage offer, so that ![\mathbb{E}[\epsilon_i | w_i]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cepsilon_i+%7C+w_i%5D%3D0&bg=ffffff&%23038;fg=333333&%23038;s=0 "\mathbb{E}[\epsilon_i | w_i]=0") . Although this assumption is a bit unrealistic, as we expect high-wage agents to also tend to have higher non-labor income, it helps keep the example simple. The model is also a bit contrived in that we treat the tax rate as unobservable, but this only makes our job more difficult.
. Although this assumption is a bit unrealistic, as we expect high-wage agents to also tend to have higher non-labor income, it helps keep the example simple. The model is also a bit contrived in that we treat the tax rate as unobservable, but this only makes our job more difficult. and
and ^N_{i=1}") and the assumed structure. In particular, the econometrician is interested in the policy-relevant parameter
and the assumed structure. In particular, the econometrician is interested in the policy-relevant parameter ") , where,
, where, \equiv \mathbb{E}_{\epsilon} \frac{\partial}{\partial \tau} C(w_i,\epsilon; \gamma, \tau)") ,
,") denotes the demand for consumption.
denotes the demand for consumption. ") is the marginal propensity for an agent with wage
is the marginal propensity for an agent with wage  is the population average marginal propensity to consume in response to the tax rate. Of course, we can solve the model analytically to find that
is the population average marginal propensity to consume in response to the tax rate. Of course, we can solve the model analytically to find that  = -\gamma w_i") and
and  , where
, where  is the average wage, but we will show that the numerical methods achieve the correct answer even when we cannot solve the model.
is the average wage, but we will show that the numerical methods achieve the correct answer even when we cannot solve the model. = \gamma (1-\tau) w_i + \gamma \epsilon_i")
 = (1-\gamma) + \frac{(1-\gamma) \epsilon_i}{ (1-\tau) w_i}")
 and
and  that agents in this model would choose. We implement this in Julia as follows:
that agents in this model would choose. We implement this in Julia as follows: ,
, ") ,
,  , and
, and  . We draw the wage to have distribution
. We draw the wage to have distribution ") , but this is arbitrary.
, but this is arbitrary.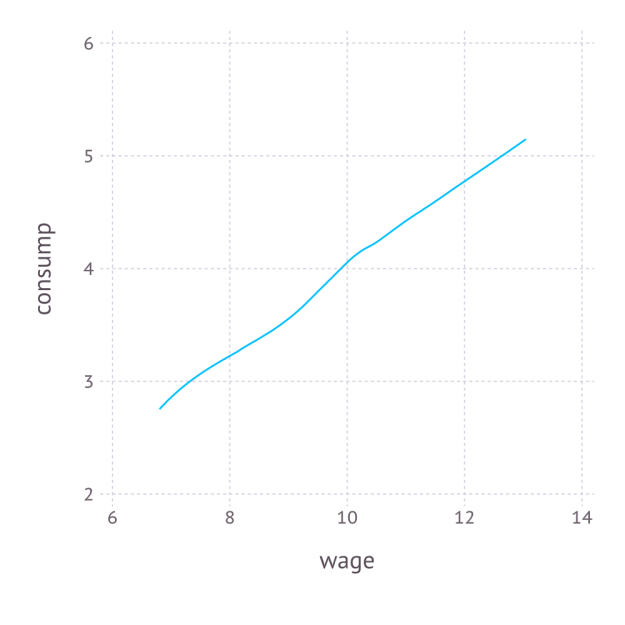
 values of
values of  :
: for each
for each  , we have enough information to simulation
, we have enough information to simulation  and
and  , for each
, for each ") and
and ") . With these, we can define the moments,
. With these, we can define the moments,![\hat{m}\left(\gamma,\tau\right)=\mathbb{E}_{\epsilon}\left[\begin{array}{c} \frac{1}{N}\sum_{i}\left[\hat{c}_{i}\left(\epsilon\right)-c_{i}\right]\\ \frac{1}{N}\sum_{i}\left[\hat{l}_{i}\left(\epsilon\right)-l_{i}\right] \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Chat%7Bm%7D%5Cleft%28%5Cgamma%2C%5Ctau%5Cright%29%3D%5Cmathbb%7BE%7D_%7B%5Cepsilon%7D%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D+%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bi%7D%5Cleft%5B%5Chat%7Bc%7D_%7Bi%7D%5Cleft%28%5Cepsilon%5Cright%29-c_%7Bi%7D%5Cright%5D%5C%5C+%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bi%7D%5Cleft%5B%5Chat%7Bl%7D_%7Bi%7D%5Cleft%28%5Cepsilon%5Cright%29-l_%7Bi%7D%5Cright%5D+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&%23038;fg=333333&%23038;s=0 "\hat{m}\left(\gamma,\tau\right)=\mathbb{E}_{\epsilon}\left[\begin{array}{c} \frac{1}{N}\sum_{i}\left[\hat{c}_{i}\left(\epsilon\right)-c_{i}\right]\\ \frac{1}{N}\sum_{i}\left[\hat{l}_{i}\left(\epsilon\right)-l_{i}\right] \end{array}\right]")
![\left(\hat{\gamma},\hat{\tau}\right)=\arg\min_{\gamma\in\left[0,1\right],\tau\in\left[0,1\right]}\hat{m}\left(\gamma,\tau\right)'W\hat{m}\left(\gamma,\tau\right)](https://s0.wp.com/latex.php?latex=%5Cleft%28%5Chat%7B%5Cgamma%7D%2C%5Chat%7B%5Ctau%7D%5Cright%29%3D%5Carg%5Cmin_%7B%5Cgamma%5Cin%5Cleft%5B0%2C1%5Cright%5D%2C%5Ctau%5Cin%5Cleft%5B0%2C1%5Cright%5D%7D%5Chat%7Bm%7D%5Cleft%28%5Cgamma%2C%5Ctau%5Cright%29%27W%5Chat%7Bm%7D%5Cleft%28%5Cgamma%2C%5Ctau%5Cright%29&bg=ffffff&%23038;fg=333333&%23038;s=0 "\left(\hat{\gamma},\hat{\tau}\right)=\arg\min_{\gamma\in\left[0,1\right],\tau\in\left[0,1\right]}\hat{m}\left(\gamma,\tau\right)'W\hat{m}\left(\gamma,\tau\right)")
 is a
is a  weighting matrix, which is only relevant when the number of moments is greater than the number of parameters, which is not true in our case, so
weighting matrix, which is only relevant when the number of moments is greater than the number of parameters, which is not true in our case, so ![\left(\hat{\gamma},\hat{\tau}\right)=\arg\min_{\gamma\in\left[0,1\right],\tau\in\left[0,1\right]}\left\{ \mathbb{E}_{\epsilon}\left[\frac{1}{N}\sum_{i}\left[\hat{c}_{i}\left(\epsilon\right)-c_{i}\right]\right]\right\} ^{2}+\left\{ \mathbb{E}_{\epsilon}\left[\frac{1}{N}\sum_{i}\left[\hat{l}_{i}\left(\epsilon\right)-l_{i}\right]\right]\right\} ^{2}](https://s0.wp.com/latex.php?latex=%5Cleft%28%5Chat%7B%5Cgamma%7D%2C%5Chat%7B%5Ctau%7D%5Cright%29%3D%5Carg%5Cmin_%7B%5Cgamma%5Cin%5Cleft%5B0%2C1%5Cright%5D%2C%5Ctau%5Cin%5Cleft%5B0%2C1%5Cright%5D%7D%5Cleft%5C%7B+%5Cmathbb%7BE%7D_%7B%5Cepsilon%7D%5Cleft%5B%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bi%7D%5Cleft%5B%5Chat%7Bc%7D_%7Bi%7D%5Cleft%28%5Cepsilon%5Cright%29-c_%7Bi%7D%5Cright%5D%5Cright%5D%5Cright%5C%7D+%5E%7B2%7D%2B%5Cleft%5C%7B+%5Cmathbb%7BE%7D_%7B%5Cepsilon%7D%5Cleft%5B%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bi%7D%5Cleft%5B%5Chat%7Bl%7D_%7Bi%7D%5Cleft%28%5Cepsilon%5Cright%29-l_%7Bi%7D%5Cright%5D%5Cright%5D%5Cright%5C%7D+%5E%7B2%7D&bg=ffffff&%23038;fg=333333&%23038;s=0 "\left(\hat{\gamma},\hat{\tau}\right)=\arg\min_{\gamma\in\left[0,1\right],\tau\in\left[0,1\right]}\left\{ \mathbb{E}_{\epsilon}\left[\frac{1}{N}\sum_{i}\left[\hat{c}_{i}\left(\epsilon\right)-c_{i}\right]\right]\right\} ^{2}+\left\{ \mathbb{E}_{\epsilon}\left[\frac{1}{N}\sum_{i}\left[\hat{l}_{i}\left(\epsilon\right)-l_{i}\right]\right]\right\} ^{2}")
") , we need to run sim_moments(params) many times and take the unweighted average across them to achieve the expectation across
, we need to run sim_moments(params) many times and take the unweighted average across them to achieve the expectation across }{dx} \approx \frac{f(x+h)-f(x-h)}{2h}") , for some small
, for some small  , as follows:
, as follows: to be approximately
to be approximately  on average, while the true value is
on average, while the true value is \times 10=-5") , so the econometrician’s problem is successfully solved.
, so the econometrician’s problem is successfully solved.