Julia is a new computing language that’s gotten a lot of attention lately (e.g., this Wired piece) and that I’ve ignored until recently. But I checked it out a few days ago and, holy crap, it’s a nice language. I’m rewriting the code in my book to use Julia instead of R and I’m almost certainly going to use it instead of R in my PhD class next fall.
So, why Julia and why not R? (And, I suppose why not Python/Matlab/other languages?)
- Multiple dispatch. So you can define a function
function TrickyAlgorithm(aThing, bThing)differently to depend on whether
aThingis a matrix of real numbers andbThingis is a vector, oraThingis a vector andbThingis a matrix, or any other combinations of data types. And you can do this without lots of tedious, potentially slow, and confusing (to people reading and maintaining the code) argument checks and conversion within the function.Note that this is kind of similar to Object Oriented Programming, but in OOP
TrickyAlgorithmwould need to be a method ofaThingorbThing. Also note that this is present in R as well. - Homoiconicity — the code can be operated on by other parts of the code. Again, R kind of has this too! Kind of, because I’m unaware of a good explanation for how to use it productively, and R’s syntax and scoping rules make it tricky to pull off. But I’m still excited to see it in Julia, because I’ve heard good things about macros and I’d like to appreciate them (I’ve started playing around with Clojure and like it a lot too…). And because stuff like this is amazing:
@devec r = exp(-abs(x-y))which devectorizes x and y (both vectors) and evaluates as
for i = 1:length(x) r[i] = exp(-abs(x[i]-y[i])) end(this example and code is from Dahua Lin’s blog post, Fast Numeric Computation in Julia). Note that “evaluates as” does not mean “gives the same answer as,” it means that the code
r = exp(-abs(x-y))is replaced with the loop by@devecand then the loop is what’s run. - Decent speed. Definitely faster than well written R; I don’t have a great feel for how well it compares to highly optimized R (using inline C++, for example), but I write one-off simulation programs and don’t write highly optimized R.And the language encourages loops, which is a relief. R discourages loops and encourages “vectorized” operations that operate on entire objects at once (which are then converted to fast loops in C…). But I use loops all the time anyway, because avoiding loops in time series applications is impossible. R’s poor support for recursion doesn’t help either.And, more to the point, I teach econometrics to graduate students. Many of them haven’t programmed before. Most of them are not going to write parts of their analysis in C++.
- The syntax is fine and unthreatening, which will help for teaching. It basically looks like Matlab done right. Matlab’s not a bad language because its programs look like they’re built out of Legos, it’s a bad language because of its horrendous implementation of functions, anonymous functions, objects, etc. Compared to R, Matlab and Julia look downright friendly. Compared to Clojure… I can’t even imagine asking first year PhD students (some with no programming experience at all) to work with a Lisp.
- The last point that’s always mentioned in these language comparisons. What about all of the R packages? There are thousands and thousands of statistical packages coded up for R, and you’re giving that up by moving to a different language.This is apparently a big concern for a lot of people, but… have you looked at the source code for these packages? Most of them are terrible! But some are good, and it might take some time to port them to Julia. Not that much time, I think, because most high-performance popular R packages are a thin layer of interoperability over a fast implementation in C or C++, so the port is just a matter of wrapping it up for Julia. And most of the well designed packages are tools for other package developers.That’s not quite true of R’s statistical graphics, though. They’re really great and could be hard to port. And that’s more or less the only thing that I’m sure that I’ll miss in Julia. (But hopefully not for too long.)
- Lastly, and this is important: the same massive quantity of packages for R is a big constraint on its future development. Breaking backwards compatibility is a big deal but avoiding it too much imposes costs.
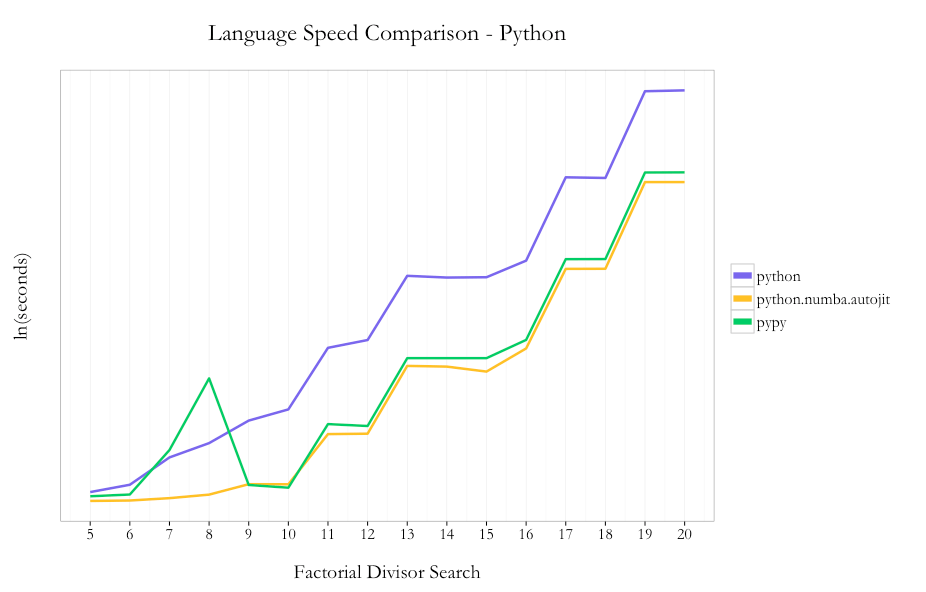
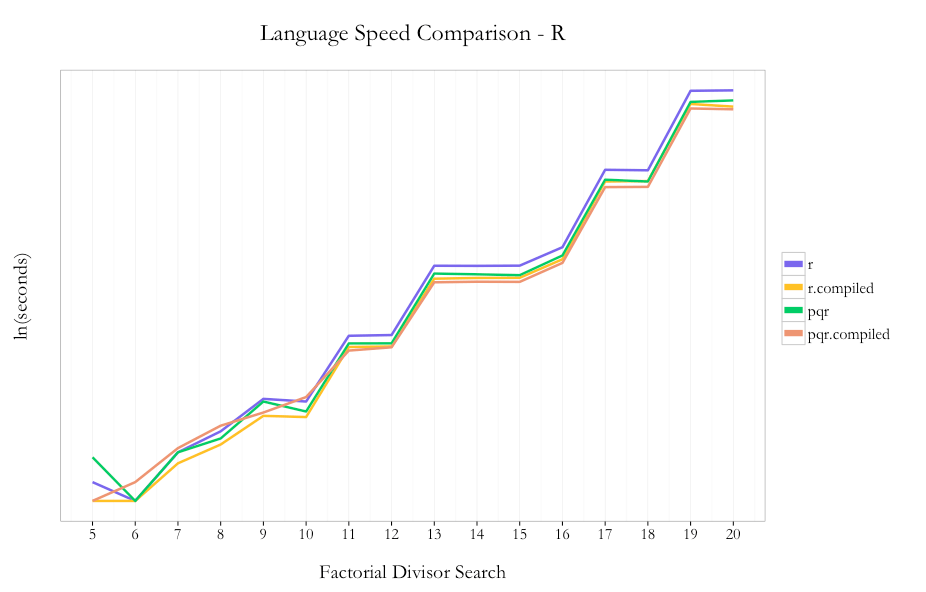
Anyway, since I converted some R code to Julia I thought it would be fun to compare speeds. The first example is used to show the sampling distribution of an average of uniform(0,1) random variables. In R, we have
rstats <- function(rerror, nobs, nsims = 500) {
replicate(nsims, mean(rerror(nobs)))}which is (I think) pretty idiomatic R (and is vectorized, so it’s supposed to be fast). Calling it gives
R> system.time(rstats(runif, 500))
[out]: user system elapsed
0.341 0.002 0.377
For comparison to the Julia results, we’re going to care about the “elapsed” result of 0.377 seconds; the “system” column isn’t relevant here. Calling it for more observations and more simulations (50,000 of each) gives
R> system.time(rstats(runif, 50000, 50000))
[out]: user system elapsed
204.184 0.217 215.526
so 216 seconds overall. And, just to preempt criticism, I ran these simulations a few times each and these results are representative; and I ran a byte-compiled version that got (unexpectedly) slightly worse performance.
Equivalent Julia code is
function rmeans(dist, nobs; nsims = 500) means = Array(Float64,nsims) for i in 1:nsims means[i] = mean(rand(dist, nobs)) end return means end
which is pretty easy to read, but I have no idea if it’s idiomatic. This is my first code in Julia. If you like to minimize lines of code and preallocation of arrays, Julia has list comprehensions and you can write the stylish one line definition (that gave similar times)
rmeans_pretty(dist, nobs; nsims = 500) = [ mean(rand(dist, nobs)) for i = 1:nsims ]
We can time (after loading the Distributions packages):
julia> @elapsed rmeans(Uniform(), 500) [out]: 0.093662961
so 0.09 seconds, or about a quarter the time as R. But (I forgot to mention earlier), Julia uses a Just In Time compiler, so the 0.09 seconds includes compilation and execution. Running it a second time gives
julia> @elapsed rmeans(Uniform(), 500) [out]: 0.004334132
which is half the time again. (Update on 3/17: as Jules pointed out in the comments, 0.004 is 1/20th of 0.09, so this is substantially faster than I’d initially thought. So we are getting into the ~100 times faster range. That’s actually a pretty exciting speed increase, but I’ll need to look into it some more. Well, that was embarrassing.)
Running the larger simulation, we have
julia> @elapsed rmeans_loop(Uniform(), 50000, nsims = 50000) [out]: 77.318591953
so the R code is a little less than three times slower here. (The compilation step doesn’t make a meaningful difference.) So, Julia isn’t hundreds of times faster, but it is noticeably faster than R, which is nice.
But speed in this sort of test isn’t the main factor. I’m really excited about multiple dispatch — it’s one of the few things in R that I really, really liked from a language standpoint. I really like what I’ve read about Julia’s support for parallelism (but need to learn more). And I like metaprogramming, even if I can’t do it myself yet. So Julia’s trying to be a fast, easy to learn, and elegantly designed language. That’s awesome. I want it to work.
ps: and it’s open source! Can’t forget that.
Filed under: Blog Tagged: julia, programming, R 
![]()