By: Bradley Setzler
Re-posted from: http://juliaeconomics.com/2014/06/15/why-i-started-a-blog-about-programming-julia-for-economics/
The following story, which I originally posted to The COBE Blog, explains why I began programming in Julia. Since then, I have found that Julia improves the performance of my other econometric estimators. However, Julia has a major disadvantage in that it lacks informative documentation and tutorials, much less accumulated discussion on sites like stackoverflow. This blog is meant to record the skills I am learning in Julia over time, to serve as a tutorial for economists and others learning the Julia programming language.
Is Julia the Future of Computational Economics?
Jorge Luis Garcia and I are currently estimating a structural econometric model of game-theoretic parent-child interaction. Using the standard implementation of Python (the code is written entirely in NumPy and SciPy with data prepared by Pandas), the optimizer ran for 24 hours, then terminated due to the 5,000 iteration limit. It was converging smoothly, but never quite arrived.
While waiting for the estimates last night (and growing increasingly impatient), I installed Julia and its packages, learned how to program in Julia, rewrote the estimation in Julia, and this morning successfully optimized the likelihood in Julia.
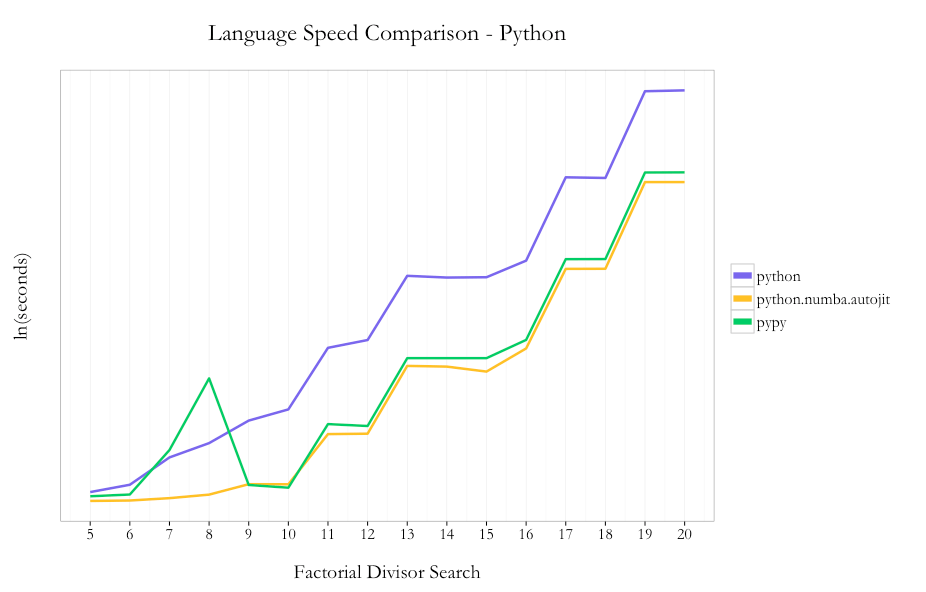
The contrast is staggering: the optimization that didn’t converge after 24 hours in Python converged after only 15 minutes in Julia while Python was still running on the same processor. Julia was already achieving a greater likelihood than Python after only 5 minutes even though Python had a 20-hour head start. They are both using the same optimization algorithm (including numerical tolerance), and the structure of the code is identical. Julia evaluates the likelihood in 0.5 seconds, while Python requires 21 seconds per evaluation, so Julia is about 40 times faster in the function evaluation, and about 100 times faster in the optimizer (I’m giving Python the benefit of the doubt even though it never converged).
The final iteration of Python was approaching the Julia optimal likelihood and getting closer; the only difference was that Julia arrived much, much more quickly. Since my next step is to bootstrap the estimator, speed is extremely important. Some practical arithmetic: on my four-core laptop, it would take two-thirds of a year to bootstrap this estimator 1,000 times, whereas Julia could do it in fewer than three days (though I’m planning to run the bootstrap in batch on the server).
I am agnostic on programming languages; I use whatever gets the answer fastest and can be reproduced most clearly, and I often use multiple languages on the same project to get the best features of each. My only claim is that Julia has taken the Python code, with minimal syntax changes, and executed the code 100 times faster for someone who had no prior experience with Julia. This was not a contrived, time-testing code; this is the estimator motivated by economic theory. The 100-fold speed increase of Julia relative to Python has been found elsewhere in computational economics.
So, is Julia the programming language of the future in structural econometrics? I’m not sure, but it seems to dominate Python and R at the moment.
Bradley J. Setzler

![]()