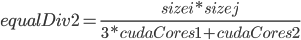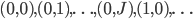Re-posted from: http://www.stochasticlifestyle.com/interfacing-xeon-phi-via-julia/
(Disclaimer: This is not a full-Julia solution for using the Phi, and instead is a tutorial on how to link OpenMP/C code for the Xeon Phi to Julia. There may be a future update where some of these functions are specified in Julia, and Intel’s compilertools.jl looks like a viable solution, but for now it’s not possible.)
Intel’s Xeon Phi has a lot of appeal. It’s an instant cluster in your computer, right? It turns out it’s not quite that easy. For one, the installation process itself is quite tricky, and the device has stringent requirements for motherboard choices. Also, making out at over a taraflop is good, but not quite as high as NVIDIA’s GPU acceleration cards.
However, there are a few big reasons why I think our interest in the Xeon Phi should be renewed. For one, Intel will be releasing its next version Knights Landing in Q3 which promises up to 8 teraflops and 16 GB of RAM. Intel has also been saying that this next platform will be much more user friendly and have improved bandwidth to allow for quicker offloading of data. Lastly, since the Xeon Phi uses X86 cores which one interfaces with via standard tools such as OpenMP and MPI, high performance parallel codes naturally transfer over to the Xeon Phi with little work (if you’ve already parallelized your code). For this reason many major HPCs such as Stampede and SuperMIC have been incorporating a Xeon Phi into every compute node. These details tell us that for high-performance computing using Xeon Phi’s to their full potential is the way forward. I am going to detail some of my advances in interfacing with the Xeon Phi via Julia.
First, let’s talk about automatic offloading
Automatic offloading allows you to offload all of your MKL-calls to the Xeon Phi automatically. This means that if you are doing lots of linear algebra on large matrices, standard operations from BLAS and Linpack like matrix multiplication * will automatically be done on the acceleration card. Details for setting up automatic offload are given by MATLAB. However, automatic offloading is a mixed blessing. First of all, there is no data persistence. If you are repeatedly using the same matrices, like in solving an evolution equation (i.e. parabolic PDE), this adds a large overhead since you’ll be sending that data back and forth every multiplication. Also, one major downside is that it does not apply to vectorized arithmetic such as .*. Sure you could hack it to be matrix multiplication by a sparse diagonal matrix, but these types of hacks really only tend to give you speedups when your vectors are large since you still incur the costs of transferring the arrays every time.
Still, it’s stupid easy to setup. You compile Julia with MKL and and setup a few environment variables and it will do it automatically. Thus you should give this a try first.
Native Execution
You can also compile code to natively execute on the Xeon Phi. However, you need to copy the files (and libraries) over the Phi via ssh and run the job from there. Thus while this is really good for C code, it’s not as easy to use when you wish to control the Phi from the computer itself as a “side job”.
Pragma-assisted Offloading
This is the route we are going to take. Pragmas are a type of syntax from OpenMP where one specifies segments of the code to be parallelized. If you’re familiar with using parallel constructs from MATLAB/Julia like parallel loops, OpenMP’s pragmas are pretty much the C version of that. For the Xeon Phi, there exists extra pragmas telling the Phi to offload. This also allows for data persistence. Lastly, for many C codes parallelized with OpenMP they are just one pragma away from working on the Phi.
Our workflow will be as follows. We will use a driver script from Julia which will set the environment and use Julia’s ccall to call the C-code with the OpenMP pragmas which will perform parallelized function calls. Notice that in this case Julia is just performing the role of glue code. The advantage is that we can prepare the data and plot the results from within Julia. The disadvantage is that we will have to write a lot of C-code. However, I am currently talking with Intel’s Developer Lab on using their CompilerTools.jl to compile Julia functions to be used on the Xeon Phi. When that’s available, I will write a tutorial on how to then replace the core functions from this script with the Julia functions. Then, the only C-code would be the code which starts the parallel loop. Let’s get started.
The Problem
We wish to solve some simple stochastic differential equations via the Euler-Maruyama method. We will specify the stochastic differential equation of the form

via functions  and
and  . In our code we will also allow the ability to have a function for the true solution in order to perform error calculations.
. In our code we will also allow the ability to have a function for the true solution in order to perform error calculations.
The Julia Code
Again, at this point the Julia code is quite simple because it is simply performing the glue. Let  be the number of simulations of we perform. Set up empty vectors for the values of
be the number of simulations of we perform. Set up empty vectors for the values of  and the true solution
and the true solution  at the endpoints. Note that we only will keep the endpoints from each simulation due to memory issues. If we were to keep the full array for thousands (or millions) of runs this would easily be more memory than the Phi could handle (or even a workstation!). We then need to specify our environmental variables. Set OMP_NUM_THREADS to be the number of compute cores on your system. We setup MIC_PREFIX, LD_IBRARY_PATH, and MIC_LD_LIBRARY_PATH so that we can dynamically link to our library. Note that this assumes that you have already sourced the compiler variables via compilervars.sh with the argument intel64. If not, you can use Julia’s run function to source the script. Lastly, we set a constant MIC_OMP_NUM_THREADS to be the number of threads the Xeon Phi will use. Since when offloading you can use all but 1 core (one manages the jobs) and each core has 4 threads, we set 240 threads (for the 5110p). Like in the case of GPUs, using more threads than cores is beneficial since the cores can utilize large vectors to do multiple calculations at once (SIMD) and other magic. We set the environment variable OFFLOAD_REPORT to 3 which will make the Phi give us details about everything it’s offloading (good for debugging). Lastly, we end by calling the library. The total code is as follows:
at the endpoints. Note that we only will keep the endpoints from each simulation due to memory issues. If we were to keep the full array for thousands (or millions) of runs this would easily be more memory than the Phi could handle (or even a workstation!). We then need to specify our environmental variables. Set OMP_NUM_THREADS to be the number of compute cores on your system. We setup MIC_PREFIX, LD_IBRARY_PATH, and MIC_LD_LIBRARY_PATH so that we can dynamically link to our library. Note that this assumes that you have already sourced the compiler variables via compilervars.sh with the argument intel64. If not, you can use Julia’s run function to source the script. Lastly, we set a constant MIC_OMP_NUM_THREADS to be the number of threads the Xeon Phi will use. Since when offloading you can use all but 1 core (one manages the jobs) and each core has 4 threads, we set 240 threads (for the 5110p). Like in the case of GPUs, using more threads than cores is beneficial since the cores can utilize large vectors to do multiple calculations at once (SIMD) and other magic. We set the environment variable OFFLOAD_REPORT to 3 which will make the Phi give us details about everything it’s offloading (good for debugging). Lastly, we end by calling the library. The total code is as follows:
M = 240000 ENV["OMP_NUM_THREADS"]=12 Us = Vector{Float64}(M) ts = Vector{Float64}(M) Ws = Vector{Float64}(M) Utrues = Vector{Float64}(M) MIC_OMP_NUM_THREADS = 240 ENV["MIC_PREFIX"]="MIC" ENV["OFFLOAD_REPORT"]=3 ENV["LD_LIBRARY_PATH"]=string(ENV["LD_LIBRARY_PATH"],":.") ENV["MIC_LD_LIBRARY_PATH"]=string(ENV["MIC_LD_LIBRARY_PATH"],":.") alg = 2 #ccall((:monte_carlo,"/home/crackauc/XeonPhiTests/EMtest/sde_solvers_noffload.so"),Void,(Cint,Ptr{Cdouble},Ptr{Cdouble},Ptr{Cdouble}),M,Us,Utrues,ts) @time ccall((:monte_carlo,"/home/crackauc/XeonPhiTests/EMtest/sde_solvers.so"),Void,(Cint,Ptr{Cdouble},Ptr{Cdouble},Ptr{Cdouble},Ptr{Cdouble},Cint,Cint),M,Us,Utrues,ts,Ws,MIC_OMP_NUM_THREADS,alg)
For more of an explanation on using the ccall function to interface with C-code, see my previous blog post. Note that the arrays Us, Utrues, ts, and Ws will be updated in place as the value of U, Utrue, t, and W at the end of the path. Thus after the job is done one can use Julia to plot the results.
Xeon Phi Driver Function
The ccall function looks for a function of the following type in a shared library named sde_solvers.so:
void monte_carlo(int M,double* Us,double* Utrues,double* ts,double* Ws,const int MIC_OMP_NUM_THREADS,int alg)
In this function we will just do a parallel for loop where each iteration calls the Euler-Maruyama solver on a different random seed. However, instead of doing a straight parallel for loop, we will put a little separation between “the parallel” and “the for” so that we can keep some persistent data to be a little more efficient.
We start by defining some constants:
double Uzero = .5; double dt = 0.00001; double T = 2.0; int N = ceil(T/dt)+1;
Now we send the job over to the Xeon Phi via the following pragma:
#pragma offload target(mic:MIC_DEV) default(none) in(Uzero,dt,T,N,MIC_OMP_NUM_THREADS,alg) out(Us:length(M))
out(Utrues:length(M)) out(ts:length(M)) out(Ws:length(M))
Note that at the top of the script we have
#ifndef MIC_DEV #define MIC_DEV 0 #endif #include <stdlib.h> #include <stdio.h> #include <omp.h> #include <mathimf.h> #include "mkl.h" #include "mkl_vsl.h"
and so MIC_DEV singles out the Xeon Phi labeled 0. Using in we send over the variables, and with out we specify the variables we want the Phi to send back. By adding default(none) we get informed if there are any variables which weren’t specified.
After that pragma, we are on the MIC. The first thing we will do is set the number of threads. I don’t know why but setting the environment variable MIC_OMP_NUM_THREADS in Julia does not set the number of MIC threads, so instead we do it manually on via the command
omp_set_num_threads(MIC_OMP_NUM_THREADS);
Next we start our parallel environment by
#pragma omp parallel default(none) shared(Uzero,alg,dt,T,N,M,ts,Us,Utrues,Ws)
Once again, default(none) will make sure no variables are accidentally set to shared, and we specify all of the inputs as shared. With this, we are now coding with that list of variables on the individual threads of the Phi. Thus we will now will setup an individual run of the SDE solver. We make arrays for time  , the Brownian path
, the Brownian path  , the solution , and the true solution . We also grab the id of the thread to setup random seeds later. This gives:
, the solution , and the true solution . We also grab the id of the thread to setup random seeds later. This gives:
int i; int tid = omp_get_thread_num(); double* t; double* W; double* U; double* Utrue; int steps; t = (double*) malloc(N*sizeof(double)); W = (double*) malloc(N*sizeof(double)); U = (double*) malloc(N*sizeof(double)); Utrue = (double*) malloc(N*sizeof(double));
Now we start our parallel for loop. Notice that by allocating these variables before the loop we have increased our efficiency since each run we will simply write over these values, saving us the time of re-allocating. In our for loop we set the initial values (since we are re-using the same arrays), call the solver algorithm, save the results at the end, and re-run. After we are done with the whole loop, then we free that arrays we made. The code is then as follows:
#pragma omp for for(i=0;i<M;i++){ t[0]=0; U[0]=Uzero; Utrue[0]=Uzero; W[0] = 0; euler_maruyama(&f,&g,&trueSol,Uzero,dt,T,t,&W,U,Utrue,tid*i*M+i); /*unique identifier tid*i*M+i since tid spacing */ Us[i] = U[N-1]; Utrues[i] = Utrue[N-1]; ts[i] = t[N-1]; Ws[i] = W[N-1]; } free(t); free(Utrue); free(U); free(W); free(Z);
Notice that tid*i*M+i has spacings larger than and  and so each value will be unique. This is then the value we can use as a random seed. The full code for the driver function is then:
and so each value will be unique. This is then the value we can use as a random seed. The full code for the driver function is then:
void monte_carlo(int M,double* Us,double* Utrues,double* ts,double* Ws,const int MIC_OMP_NUM_THREADS,int alg){ double Uzero = .5; double dt = 0.00001; double T = 2.0; int N = ceil(T/dt)+1; #pragma offload target(mic:MIC_DEV) default(none) in(Uzero,dt,T,N,MIC_OMP_NUM_THREADS,alg) out(Us:length(M)) out(Utrues:length(M)) out(ts:length(M)) out(Ws:length(M)) { omp_set_num_threads(MIC_OMP_NUM_THREADS); #pragma omp parallel default(none) shared(Uzero,alg,dt,T,N,M,ts,Us,Utrues,Ws) { int i; int tid = omp_get_thread_num(); double* t; double* W; double* U; double* Utrue; int steps; t = (double*) malloc(N*sizeof(double)); W = (double*) malloc(N*sizeof(double)); U = (double*) malloc(N*sizeof(double)); Utrue = (double*) malloc(N*sizeof(double)); #pragma omp for for(i=0;i<M;i++){ t[0]=0; U[0]=Uzero; Utrue[0]=Uzero; W[0] = 0; euler_maruyama(&f,&g,&trueSol,Uzero,dt,T,t,&W,U,Utrue,tid*i*M+i); /*unique identifier tid*i*M+i since tid spacing */ Us[i] = U[N-1]; Utrues[i] = Utrue[N-1]; ts[i] = t[N-1]; Ws[i] = W[N-1]; } free(t); free(Utrue); free(U); free(W); free(Z); } } }
Notice I left out the extra algorithms. When I put this in a package (and in my soon to be submitted code for a publication) I have different choices for the solver, but here we will just have Euler-Maruyama.
The Inner Functions
Before we get to the solver, notice that euler_maruyama takes in three functions by handle. However, since these will be executed on the Xeon Phi we decorate them with __attribute__((target(mic))). However, I will leave off these declarations since we can instead have them be put on automatically by a compiler command (and this makes it easier to re-compile to be a Xeon Phi free code). Thus the SDE functions are simply
double f(double t,double x){ return (1.0/20.0)*x; } double g(double t,double x){ return (1.0/10.0)*x; } double trueSol(double t, double Uzero,double W){ return Uzero*exp(((1.0/20.0)-((1.0/10.0)*(1.0/10.0))/2.0)*t + (1.0/10.0)*W); }
Thus the SDE is

which a mathematician would call Geometric Brownian Motion or what someone in finance would know of as the Black-Scholes equation. Our inner function euler_maruyama is then the standard loop for solving via Euler-Maruyama where we replace any instance of  with a small real number and we replace
with a small real number and we replace  with normal random variables with zero mean and variance . The only tricky part is getting normal random variables, but I used Intel’s VSL library for generating these. The code for solving the Euler-Maruyama equations are then
with normal random variables with zero mean and variance . The only tricky part is getting normal random variables, but I used Intel’s VSL library for generating these. The code for solving the Euler-Maruyama equations are then
void euler_maruyama(double (*f)(double,double),double (*g)(double,double),double (*trueSol)(double,double,double),double Uzero,double dt, double T,double* t,double** W,double* U,double* Utrue,int id){ int N = ceil(T/dt)+1; *W = (double*) malloc(N*sizeof(double)); VSLStreamStatePtr stream; vslNewStream(&stream,VSL_BRNG_MT19937,20+id); vdRngGaussian(VSL_RNG_METHOD_GAUSSIAN_BOXMULLER,stream,N,*W,0.0f,1.0f); (*W)[0] = 0.0f; int i; double dW; double sqdt = sqrt(dt); for(i=1;i<N;i++){ /* dW = 0; */ dW = sqdt* (*W)[i]; t[i] = t[i-1] + dt; (*W)[i] = (*W)[i-1] + dW; U[i] = U[i-1] + dt*f(t[i-1],U[i-1]) + g(t[i-1],U[i-1])*dW; Utrue[i] = trueSol(t[i],Uzero,(*W)[i]); } vslDeleteStream(&stream); }
Notice that this part is nothing special and quite close to what you’d write in  . However, we do note that since we want the value of at the end of the run outside of this function, and we allocate within the function, we have to pass by reference via &W and thus every time it is used we have to deference it via *W. Other than that there’s nothing fancy here.
. However, we do note that since we want the value of at the end of the run outside of this function, and we allocate within the function, we have to pass by reference via &W and thus every time it is used we have to deference it via *W. Other than that there’s nothing fancy here.
Compilation
This is always the hardest part. However, notice that if we just take away the offload pragma this is perfectly good OpenMP code! You can do this from the compiler to first check your code. The compilation command is as follows:
icc -mkl -O3 -openmp -fpic -diag-disable 10397 -no-offload -Wno-unknown-pragmas -std=c99 -qopt-report -qopt-report-phase=vec -shared sde_solvers.c -o sde_solvers.so
Most of it is setting up offload reports and libraries, but the important part to notice is that -no-offload is the part that turns off the offload pragma. Give this a try and it should parallelize on the CPU. Now, to compile for the Phi, we use the command
icc -mkl -O3 -openmp -fpic -diag-disable 10397 -qoffload -Wno-unknown-pragmas -std=c99 -qopt-report -qopt-report-phase=vec -shared sde_solvers.c -offload-attribute-target=mic -o sde_solvers.so
Notice that the command -offload-attribute-target=mic is required if you do not put __attribute__((target(mic))) in front of each function that is called when offloaded. I prefer to not put the extra tags because icc required that I delete them to re-compile for the CPU. In this case, we simply get rid of that compiler directive and change to -no-offload and we have working CPU code. Thus you can see how to transfer back and forth between the two via compilation.
After doing this you should be able to call the code from Julia, have it solve the code on the Phi, and then return the result to Julia.
Future Steps
Notice that the functions , , and  are simple functions which we pass by pointer into the solver. Julia already has ways to pass function pointers which I go over in my previous tutorial, though since they are not compiled with the __attribute__((target(mic))) flag they will not work on the Phi. Hopefully Intel’s compilertools.jl will support this in the near future. When that’s the case, these functions could be specified from within Julia to allow us to create libraries where we can use Julia-specified functions as the input.
are simple functions which we pass by pointer into the solver. Julia already has ways to pass function pointers which I go over in my previous tutorial, though since they are not compiled with the __attribute__((target(mic))) flag they will not work on the Phi. Hopefully Intel’s compilertools.jl will support this in the near future. When that’s the case, these functions could be specified from within Julia to allow us to create libraries where we can use Julia-specified functions as the input.
However, this gives a nice template for performing any kind of Monte Carlo simulation or anything else that uses a parallel for loop. This wrapper will form the basis of a library I am creating for stochastic (partial) differential equations. More on that later. In the meantime, have fun experimenting with the Phi!
The post Interfacing with a Xeon Phi via Julia appeared first on Stochastic Lifestyle.



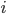

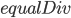





![cudaCores=[2946]](https://i2.wp.com/www.stochasticlifestyle.com/wp-content/plugins/latex/cache/tex_77145979839f0aa461fb95033ff1f5a4.gif)
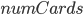
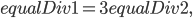

![cudaCores[i]](https://i2.wp.com/www.stochasticlifestyle.com/wp-content/plugins/latex/cache/tex_fcdf951de22da0e6201f3ff421a4614d.gif)