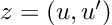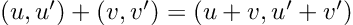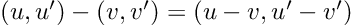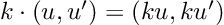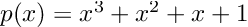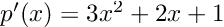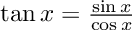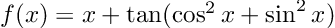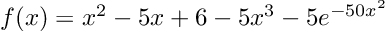Re-posted from: http://www.stochasticlifestyle.com/semantic-versioning-semver-is-flawed-and-downgrade-ci-is-required-to-fix-it/
Semantic versioning is great. If you don’t know what it is, it’s just a versioning scheme for software that goes MAJOR.MINOR.PATCH, where
- MAJOR version when you make incompatible API changes
- MINOR version when you add functionality in a backward compatible manner
- PATCH version when you make backward compatible bug fixes
That’s all it is, but it’s a pretty good system. If you see someone has updated their package from v3.2.0 to v3.2.1, then you know that you can just take that update because it’s just a patch, it won’t break your code. You can easily accept patch updates. Meanwhile, if you see they released v3.3.0, then you know that some new features were added, but it’s safe for you to update. This allows you to be compatible with v3.3.0 so that if a different package requires it, great you can both use it! Thus a lot of version updates to your dependencies can be accepted without even thinking about it. However, when you see that v4.0.0, you know that your dependency broke some APIs, so you need to do that compatibility bump automatically. Thus the semvar system makes it much easier to maintain large organizations of packages since the number of manual version bumps that you need to do are rather small.
Because of how useful this can be, many package managers have incorporated a form of semantic versioning into its system. Julia’s package manager, Rust’s package manager, Node’s package manager, and more all have ways that integrate semantic versioning into its systems, making it easy to automatically accept dependency updates and thus keeper a wider set of compatibility than can effectively done manually. It’s a vital part of our current dependency system.
Okay if it’s great, then how can it be flawed?
Semver is flawed for two reasons:
- The definition of “breaking” is vague and ill-defined at its edges
- Current tooling does not accurately check for Semver compatibility
Breaking: a great concept but with unclear boundaries
The first point is somewhat known and is best characterized by the classic XKCD comic:

Any change can break code. It’s really up to the definition of “what is breaking”. There’s many nuances:
- “Breaking” only applies to the “public facing API”, i.e. things that users interact with. If anything changing was considered breaking then every change would be a breaking change, so in order for semver to work you have to have some sense of what is considered internals and what is considered public. Julia in its next recent version has a new “public” keyword to declare certain internals as public, i.e. things which are exported and specifically chosen values in a package module are considered internal by default. If you have many users, you will still find someone say “but I use function __xxxxyyyz_internal because the API doesn’t allow me to pass mycacheunsafemathbeware optimally”, but at least you can blame them for it. This is the most solvable issue of semver and simply requires due diligence and sticking to a clear system for what’s exposed and what’s not. That’s a bit harder in dynamic languages, but as shown there are systems in place for this.
- What is considered “breaking” in terms of functionality can have some fuzzy edges. I work on numerical solvers and connections to machine learning (scientific machine learning or SciML). If someone calls the ODE solver with abstol=1e-6 and reltol=1e-3, then what is returned is an approximation to the ODE’s solution with a few digits of accuracy (there’s some details in here I will ignore). If a change is made internally to the package, say more SIMD for better performance, which causes the result to change in the 12 digit, is that breaking? Because the ODE solver only is guaranteeing at most 3-6 digits of accuracy, probably not. But what if the 6th digit changes? The 5th? If the built-in sin function in the language changes in the 15th digit of accuracy, is that breaking? Most documentation strings don’t explicitly say “this is computed to 1ulp (units in the last place)”, so it’s not always clear what one is truly guaranteed from a numerical function. If someone improves the performance of a random number generator and now the random numbers for the same seed are different, is this breaking? Were you guaranteed that wasn’t going to change? People will argue all day about some of these edge cases, “it broke my tests because I set the random number seed and now it broke”. Look at any documentation, for example numpy.random.rand, and it won’t clarify these details on you can rely on to change and not change. This granularity is a discussion with a vague boundary.
- One man’s bug fix is another man’s breaking change. You may have intended for all instantiations of f(x::T) (or T.f(x)) to return an integer, but one of them returned a float. So what do you do? You go fix it, make them all return floats, and add documentation on the interface that they all return a floating point value and implement some interface to enforce it across all functions… and then the issues roll in “you broke my code because I required that this version of the function returned an integer!”. A bugfix is by definition correcting an unintended behavior. However, someone has to define “unintended”, and your users may not be able to read your brain and may consider what was “intended” differently. I’m not sure there really is a solution to this because a bug is by definition unintended: if you knew it was there then you would have either fixed it or documented it earlier. But left with no documentation on what to do, the user may thing the behavior is intentional and use it.
- Adding new functionality may have unintended consequences. You may have previously threw an error in a given case, but now return an approximation. The user may only want exact solutions to some math function f(x), so they relied on the error throw before in order to know if the solution would have been exactly calculable. Your new approximation functionality that you just released with a nice blog post thus just broke somebody’s code. So is it a major update, or a minor update? You never “intended” for only giving exact solutions, the error message might’ve even said “we intend to add this case in the near future with an approximation”, but you still broke their code.
As Churchill said, “democracy is the worst form of government, except for all the others”. In this case, semver is great because it conveys useful information, but we shouldn’t get ahead of ourselves and thus assume it does everything perfectly. Its definitions can be vague and it requires discussion to figure out whether something is breaking or a patch sometimes.
But if it does fail, hopefully our tooling can help us know. We all have continuous integration and continuous deployment (CI/CD), that helps us handle semver… right?
Standard CI/CD Systems are Insufficient to Check Semver Compatibility
I’m no chump so I set my versioning to use semantic versioning. My Project.tomls are all setup to put lower bounds, for example I list out all of my version requirements like a champ (if you’re not familiar with Julia’s package manager, everything defaults to semver and thus DiffEqBase = “6.41” in the compat implicitly means any 6.x with x>41, but 7 is not allowed). We laugh in the face of the Python PyPI system because our package registration system rejects any package (new or new version) which does not have an upper bound. Every package is required to have compatibilities specified, and thus random breakage is greatly reduced. We have forced all package authors to “do the right thing” and users have ultimately one. Package it up, we’re done here.
But then… users… see some breakage? They make a post where they show you that user your package failed. How could that happen? Well it goes back to part one that there are some edges in semantic versioning that may have creeped in somewhere. But many times what has happened is that the authors have simply forgotten what their lower bound means. v3.3.0 introduced the function f(x) in PkgA so when you started to use that function from the dependency, you set the lower bound there and life is good. g(x) was introduced in v3.4.0 and a few years later PkgA is at 3.11.2 you learn about it and go “cool PkgA is great!”, you start using g(x), your CI system says everything is fine, and then a user pops up and says your package is broken for them. When digging into the logs, you see that there’s some other package that only allows
The real core issue here is that semantic versioning is generally inadequately tested. In theory, if I put a lower bound saying I accept v3.3.0 and anything above it until v4, then I might be saying I am allowing more than 100 versions of PkgA. If I also have a PkgB with similar semantic versioning, I could be allowing 100 variations of that as well. However, the way everyone’s CI/CD system runs is to take the latest version of the packages. Okay, maybe for some major dependency like the standard library you list ‘Programming Language :: Python :: 3.8’, ‘Programming Language :: Python :: 3.9’, … to test multiple versions of that, but are you checking the 100,000 permutations of all allowed dependency versions? Almost certainly not. Not only have I not seen this, it’s also just infeasible to do in practice.
But as a shortcut, what you should be doing is at least checking the most edgy of edge cases. If I state v3.3.0 is my allowed lower bound, most CI systems will simply grab the latest v3.y.z with y and z as big as possible. However, I should at least have one run with v3.3.0 to see if it’s still sensible. This would have caught that g(x) was not defined in v3.4.0. While this wouldn’t fix all issues with semantic versioning, it can at least identify many of them pretty straightforwardly.
We call this scheme “Downgrade CI”, i.e. downgrade all dependencies to their minimum versions and run it. Most users will only ever see the maximum versions so sure it doesn’t matter to most people, but as people add more and more into their environment they will start to see earlier versions, and it’s these minimum versions that are the true key to whether your package will give a sensible environment, not the version maximums which semver puts so much effort into!
Setting up Downgrade CI
Okay, so hopefully I’ve convinced you that semver is not a magical solution to all compatibility problems, it’s a nice tool but not a silver bullet, and you need to have some form of downgrade CI. How do you actually accomplish this? Thankfully the Julia ecosystem has a julia-downgrade-compat-action which sets up Github Actions CI to automatically run the package versions with this downgrade idea in mind. If you’re scared of trying to figure that out, don’t worry and just copy-paste a script out of SciML. For example, from SciMLBase.jl:
name: Downgrade
on:
pull_request:
branches:
- master
paths-ignore:
- 'docs/**'
push:
branches:
- master
paths-ignore:
- 'docs/**'
jobs:
test:
runs-on: ubuntu-latest
strategy:
matrix:
version: ['1']
steps:
- uses: actions/checkout@v4
- uses: julia-actions/setup-julia@v1
with:
version: ${{ matrix.version }}
- uses: cjdoris/julia-downgrade-compat-action@v1
with:
skip: Pkg,TOML
- uses: julia-actions/julia-buildpkg@v1
- uses: julia-actions/julia-runtest@v1
This will add a new set of CI tests which run in the downgraded form and ensure your lower bounds are up to date. Will this solve all version compatibility issues? No, but hopefully this catches most of the major classes of issues.
Conclusion
In conclusion, use downgrade CI because semver isn’t perfect and while it does give a decent idea as to handling of upper bounds, lower bounds still need to be handled quite manually and “manual” is synonym for “can break”.
The post Semantic Versioning (Semver) is flawed, and Downgrade CI is required to fix it appeared first on Stochastic Lifestyle.