By: Logan Kilpatrick
The IEEE just released their annual report on the top programming language which can be found here…
By: Logan Kilpatrick
The IEEE just released their annual report on the top programming language which can be found here…
By: Bradley Setzler
Re-posted from: http://juliaeconomics.com/2016/02/09/an-introduction-to-structural-econometrics-in-julia/
This tutorial is adapted from my Julia introductory lecture taught in the graduate course Practical Computing for Economists, Department of Economics, University of Chicago.
The tutorial is in 5 parts:
Perhaps the greatest obstacle to using Julia in the past has been the absence of an easy-to-install IDE. There used to be an IDE called Julia Studio which was as easy to use as the popular RStudio for R. Back then, you could install and run Julia + Julia Studio in 5mins, compared to the hours it could take to install Python and its basic packages and IDE. When Julia version 0.3.X was released, Julia Studio no longer worked, and I recommended the IJulia Notebook, which requires the installation of Python and IPython just to use Julia, so any argument that Julia is more convenient to install than Python was lost.
Now, with Julia version 0.4.X, Juno has provided an excellent IDE that comes pre-bundled with Julia for convenience, and you can install Julia + Juno IDE in 5mins. Here are some instructions to help you through the installation process:
Pkg.update()
Pkg.add("Ipopt")
Pkg.build("Ipopt")
Pkg.add("JuMP")
Pkg.build("JuMP")
Pkg.add("GLM")
Pkg.add("KernelEstimator")
To motivate our application, we consider a very simple economic model, which I have taught previously in the mathematical economics course for undergraduates at the University of Chicago. Although the model is analytically simple, the econometrics become sufficiently complicated to warrant the Method of Simulated Moments, so this serves us well as a teachable case.
Let 

 =")

where 
w_i(1-l_i)+\epsilon_i")
where 


The agent’s problem is to maximize ")
![\mathbb{E}[\epsilon_i | w_i]=0](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Cepsilon_i+%7C+w_i%5D%3D0&bg=ffffff&%23038;fg=333333&%23038;s=0 "\mathbb{E}[\epsilon_i | w_i]=0")
The goal of the econometrician is to identify the model parameters 
^N_{i=1}")
")
 \equiv \mathbb{E}_{\epsilon} \frac{\partial}{\partial \tau} C(w_i,\epsilon; \gamma, \tau)")
and ")
")

 = -\gamma w_i")


The replication code for this section is available here.
To generate data that follows the above model, we first solve analytically for the demand functions for consumption and leisure. In particular, they are,
Thus, we need only draw values of 

####### Set Simulation Parameters ######### srand(123) # set the seed to ensure reproducibility N = 1000 # set number of agents in economy gamma = .5 # set Cobb-Douglas relative preference for consumption tau = .2 # set tax rate ####### Draw Income Data and Optimal Consumption and Leisure ######### epsilon = randn(N) # draw unobserved non-labor income wage = 10+randn(N) # draw observed wage consump = gamma*(1-tau)*wage + gamma*epsilon # Cobb-Douglas demand for c leisure = (1.0-gamma) + ((1.0-gamma)*epsilon)./((1.0-tau)*wage) # Cobb-Douglas demand for l
This code is relatively self-explanatory. Our parameter choices are 
")


")
We combine the variables into a DataFrame, and export the data as a CSV file. In order to better understand the data, we also non-parametrically regress
####### Organize, Describe, and Export Data #########
using DataFrames
using Gadfly
df = DataFrame(consump=consump,leisure=leisure,wage=wage,epsilon=epsilon) # create data frame
plot_c = plot(df,x=:wage,y=:consump,Geom.smooth(method=:loess)) # plot E[consump|wage] using Gadfly
draw(SVG("plot_c.svg", 4inch, 4inch), plot_c) # export plot as SVG
writetable("consump_leisure.csv",df) # export data as CSV
Again, the code is self-explanatory. The regression graph produced by the plot function is:
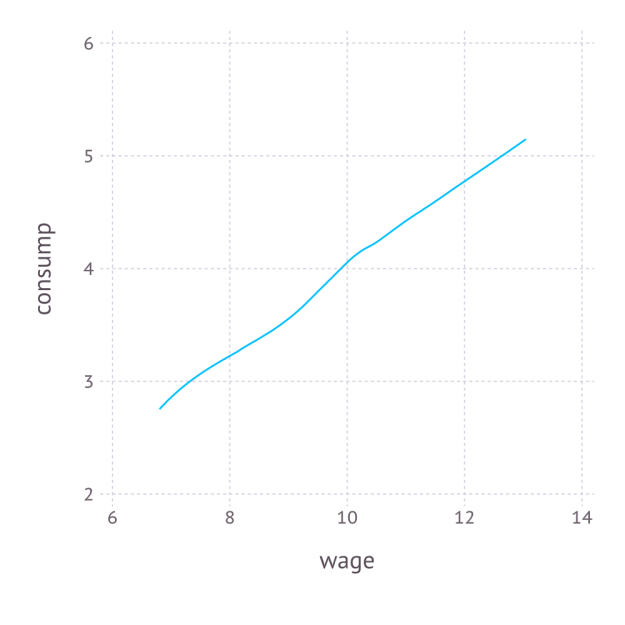
The replication code for this section is available here.
We now use constrained numerical optimization to generate optimal consumption and leisure data without analytically solving for the demand function. We begin by importing the data and the necessary packages:
####### Prepare for Numerical Optimization #########
using DataFrames
using JuMP
using Ipopt
df = readtable("consump_leisure.csv")
N = size(df)[1]
Using the JuMP syntax for non-linear modeling, first we define an empty model associated with the Ipopt solver, and then add 
m = Model(solver=IpoptSolver()) # define empty model solved by Ipopt algorithm @defVar(m, c[i=1:N] >= 0) # define positive consumption for each agent @defVar(m, 0 <= l[i=1:N] <= 1) # define leisure in [0,1] for each agent
This syntax is especially convenient, as it allows us to define vectors of parameters, each satisfying the natural inequality constraints. Next, we define the budget constraint, which also follows this convenient syntax:
@addConstraint(m, c[i=1:N] .== (1.0-t)*(1.0-l[i]).*w[i] + e[i] ) # each agent must satisfy the budget constraint
Finally, we define a scalar-valued objective function, which is the sum of each individual’s utility:
@setNLObjective(m, Max, sum{ g*log(c[i]) + (1-g)*log(l[i]) , i=1:N } ) # maximize the sum of utility across all agents
Notice that we can optimize one objective function instead of optimizing
status = solve(m) # run numerical optimization c_opt = getValue(c) # extract demand for c l_opt = getValue(l) # extract demand for l
To make sure it worked, we compare the consumption extracted from this numerical approach to the consumption we generated previously using the true demand functions:
cor(c_opt,array(df[:consump])) 0.9999999998435865
Thus, we consumption values produced by the numerically optimizer’s approximation to the demand for consumption are almost identical to those produced by the true demand for consumption. Putting it all together, we create a function that can solve for optimal consumption and leisure given any particular values of 
function hh_constrained_opt(g,t,w,e) m = Model(solver=IpoptSolver()) # define empty model solved by Ipopt algorithm
@defVar(m, c[i=1:N] >= 0) # define positive consumption for each agent
@defVar(m, 0 <= l[i=1:N] <= 1) # define leisure in [0,1] for each agent
@addConstraint(m, c[i=1:N] .== (1.0-t)*(1.0-l[i]).*w[i] + e[i] ) # each agent must satisfy the budget constraint
@setNLObjective(m, Max, sum{ g*log(c[i]) + (1-g)*log(l[i]) , i=1:N } ) # maximize the sum of utility across all agents
status = solve(m) # run numerical optimization
c_opt = getValue(c) # extract demand for c
l_opt = getValue(l) # extract demand for l
demand = DataFrame(c_opt=c_opt,l_opt=l_opt) # return demand as DataFrame
end
hh_constrained_opt(gamma,tau,array(df[:wage]),array(df[:epsilon])) # verify that it works at the true values of gamma, tau, and epsilon
The replication codes for this section are available here.
We saw in the previous section that, for a given set of model parameters 



")
")
which is equal to zero under the model assumptions. A method of simulated moments (MSM) approach to estimate
where 

Assuming we know the distribution of
function sim_moments(params) this_epsilon = randn(N) # draw random epsilon ggamma,ttau = params # extract gamma and tau from vector this_demand = hh_constrained_opt(ggamma,ttau,array(df[:wage]),this_epsilon) # obtain demand for c and l c_moment = mean( this_demand[:c_opt] ) - mean( df[:consump] ) # compute empirical moment for c l_moment = mean( this_demand[:l_opt] ) - mean( df[:leisure] ) # compute empirical moment for l [c_moment,l_moment] # return vector of moments end
In order to estimate ")
Previously, I presented a convenient approach for parallelization in Julia. The idea is to initialize processors with the addprocs() function in an “outer” script, then import all of the needed data and functions to all of the different processors with the require() function applied to an “inner” script, where the needed data and functions are already managed by the inner script. This is incredibly easy and much simpler than the manual spawn-and-fetch approaches suggested by Julia’s official documentation.
In order to implement the parallelized method of simulated moments, the function hh_constrained_opt() and sim_moments() are stored in a file called est_msm_inner.jl. The following code defines the parallelized MSM and then minimizes the MSM objective using the optimize command set to use the Nelder-Mead algorithm from the Optim package:
####### Prepare for Parallelization #########
addprocs(3) # Adds 3 processors in parallel (the first is added by default)
print(nprocs()) # Now there are 4 active processors
require("est_msm_inner.jl") # This distributes functions and data to all active processors
####### Define Sum of Squared Residuals in Parallel #########
function parallel_moments(params)
params = exp(params)./(1.0+exp(params)) # rescale parameters to be in [0,1]
results = @parallel (hcat) for i=1:numReps
sim_moments(params)
end
avg_c_moment = mean(results[1,:])
avg_l_moment = mean(results[2,:])
SSR = avg_c_moment^2 + avg_l_moment^2
end
####### Minimize Sum of Squared Residuals in Parallel #########
using Optim
function MSM()
out = optimize(parallel_moments,[0.,0.],method=:nelder_mead,ftol=1e-8)
println(out) # verify convergence
exp(out.minimum)./(1.0+exp(out.minimum)) # return results in rescaled units
end
Parallelization is performed by the @parallel macro, and the results are horizontally concatenated from the various processors by the hcat command. The key tuning parameter here is numReps, which is the number of draws of
numReps = 12 # set number of times to simulate epsilon gamma_MSM, tau_MSM = MSM() # Perform MSM gamma_MSM 0.49994494921381816 tau_MSM 0.19992279518894465
Finally, given the MSM estimates of }{dx} \approx \frac{f(x+h)-f(x-h)}{2h}")

function Dconsump_Dtau(g,t,h) opt_plus_h = hh_constrained_opt(g,t+h,array(df[:wage]),array(df[:epsilon])) opt_minus_h = hh_constrained_opt(g,t-h,array(df[:wage]),array(df[:epsilon])) (mean(opt_plus_h[:c_opt]) - mean(opt_minus_h[:c_opt]))/(2*h) end barpsi_MSM = Dconsump_Dtau(gamma_MSM,tau_MSM,.1) -5.016610457903023
Thus, we estimate the policy parameter 

\times 10=-5")
Bradley Setzler

![]()
By: Bradley Setzler
Re-posted from: https://juliaeconomics.com/2014/09/02/selection-bias-corrections-in-julia-part-1/
Selection bias arises when a data sample is not a random draw from the population that it is intended to represent. This is especially problematic when the probability that a particular individual appears in the sample depends on variables that also affect the relationships we wish to study. Selection bias corrections based on models of economic behavior were pioneered by the economist James J. Heckman in his seminal 1979 paper.
For an example of selection bias, suppose we wish to study the effectiveness of a treatment (a new medicine for patients with a particular disease, a preschool curriculum for children facing particular disadvantages, etc.). A random sample is drawn from the population of interest, and the treatment is randomly assigned to a subset of this sample, with the remaining subset serving as the untreated (“control”) group. If the subsets followed instructions, then the resulting data would serve as a random draw from the data generating process that we wish to study.
However, suppose the treatment and control groups do not comply with their assignments. In particular, if only some of the treated benefit from treatment while the others are in fact harmed by treatment, then we might expect the harmed individuals to leave the study. If we accepted the resulting data as a random draw from the data generating process, it would appear that the treatment was much more successful than it actually was; an individual who benefits is more likely to be present in the data than one who does not benefit.
Conversely, if treatment were very beneficial, then some individuals in the control group may find a way to obtain treatment, possibly without our knowledge. The benefits received by the control group would make it appear that the treatment was less beneficial than it actually was; the receipt of treatment is no longer random.
In this tutorial, I present some parameterized examples of selection bias. Then, I present examples of parametric selection bias corrections, evaluating their effectiveness in recovering the data generating processes. Along the way, I demonstrate the use of the GLM package in Julia. A future tutorial demonstrates non-parametric selection bias corrections.
Example 1: Selection on a Normally-Distributed Unobservable
Suppose that we wish to study of the effect of the observable variable 


where 
")


=1")

and the probability is zero otherwise. This selection rule ensures that, among the individuals in the data (the 
To see the problem, consider the following simulation of the above process in which
srand(2) N = 1000 X = randn(N) epsilon = randn(N) beta_0 = 0. beta_1 = 1. Y = beta_0 + beta_1.*X + epsilon populationData = DataFrame(Y=Y,X=X,epsilon=epsilon) selected = X.>epsilon sampleData = DataFrame(Y=Y[selected],X=X[selected],epsilon=epsilon[selected])
There are 1,000 individuals in the population data, but 492 of them are selected to be included in the sample data. The covariance between X and epsilon in the population data is,
cov(populationData[:X],populationData[:epsilon]) 0.00861456704877879
which is approximately zero, but in the sample data, it is,
cov(sampleData[:X],sampleData[:epsilon]) 0.32121357192108513
which is approximately 0.32.
Now, we regress 
linreg(array(populationData[:X]),array(populationData[:Y]))
2-element Array{Float64,1}:
-0.027204
1.00882
linreg(array(sampleData[:X]),array(sampleData[:Y]))
2-element Array{Float64,1}:
-0.858874
1.4517
where, in Julia 0.3.0, the command array() replaces the old command matrix() in converting a DataFrame into a numerical Array. This simulation demonstrates severe selection bias associated with using the sample data to estimate the data generating process instead of the population data, as the true parameters, 
Correction 1: Heckman (1979)
The key insight of Heckman (1979) is that the correlation between
![\mathbb{E}\left[Y_i\Big|X_i,i\in\mathcal{S}\right]=\mathbb{E}\left[\beta_0 + \beta_1X_i+\epsilon_i\Big|X_i,i\in\mathcal{S}\right]=\beta_0 + \beta_1X_i+\mathbb{E}\left[\epsilon_i\Big|X_i,i\in\mathcal{S}\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BY_i%5CBig%7CX_i%2Ci%5Cin%5Cmathcal%7BS%7D%5Cright%5D%3D%5Cmathbb%7BE%7D%5Cleft%5B%5Cbeta_0+%2B+%5Cbeta_1X_i%2B%5Cepsilon_i%5CBig%7CX_i%2Ci%5Cin%5Cmathcal%7BS%7D%5Cright%5D%3D%5Cbeta_0+%2B+%5Cbeta_1X_i%2B%5Cmathbb%7BE%7D%5Cleft%5B%5Cepsilon_i%5CBig%7CX_i%2Ci%5Cin%5Cmathcal%7BS%7D%5Cright%5D&bg=ffffff&%23038;fg=333333&%23038;s=0 "\mathbb{E}\left[Y_i\Big|X_i,i\in\mathcal{S}\right]=\mathbb{E}\left[\beta_0 + \beta_1X_i+\epsilon_i\Big|X_i,i\in\mathcal{S}\right]=\beta_0 + \beta_1X_i+\mathbb{E}\left[\epsilon_i\Big|X_i,i\in\mathcal{S}\right]")
Furthermore, using the conditional density of the standard Normally distributed
![\mathbb{E}\left[\epsilon_i\Big|X_i,i\in\mathcal{S}\right]=\mathbb{E}\left[\epsilon_i\Big|X_i,X_i>\epsilon_i\right]=\frac{-\phi\left(X_i\right)}{\Phi\left(X_i\right)}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Cepsilon_i%5CBig%7CX_i%2Ci%5Cin%5Cmathcal%7BS%7D%5Cright%5D%3D%5Cmathbb%7BE%7D%5Cleft%5B%5Cepsilon_i%5CBig%7CX_i%2CX_i%3E%5Cepsilon_i%5Cright%5D%3D%5Cfrac%7B-%5Cphi%5Cleft%28X_i%5Cright%29%7D%7B%5CPhi%5Cleft%28X_i%5Cright%29%7D&bg=ffffff&%23038;fg=333333&%23038;s=0 "\mathbb{E}\left[\epsilon_i\Big|X_i,i\in\mathcal{S}\right]=\mathbb{E}\left[\epsilon_i\Big|X_i,X_i>\epsilon_i\right]=\frac{-\phi\left(X_i\right)}{\Phi\left(X_i\right)}")
which is called the inverse Mills ratio, where 

Returning to our simulation, the inverse Mills ratio is added to the sample data as,
sampleData[:invMills] = -pdf(Normal(),sampleData[:X])./cdf(Normal(),sampleData[:X])
Then, we run the regression corresponding to the sample moment condition,
linreg(array(sampleData[[:X,:invMills]]),array(sampleData[:Y]))
3-element Array{Float64,1}:
-0.166541
1.05648
0.827454
We see that the estimate for 

linreg(array(sampleData[[:X,:invMills]]),array(sampleData[:Y]))
3-element Array{Float64,1}:
-0.00417033
1.00697
0.991503
which are very close to the true parameter values.
Note that this analysis generalizes to the case in which 

which is the case considered by Heckman (1979). The only difference is that the coefficients 


As a matter of terminology, the process of estimating 

Example 2: Probit Selection on Observables
Suppose that we wish to know the mean and variance of
=F\left(X_i\right)")
where 
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&%23038;fg=333333&%23038;s=0 "[0,1]")
\neq 0")
srand(2)
N = 10000
populationData = DataFrame(rand(MvNormal([0,0.],[1 .5;.5 1]),N)')
names!(populationData,[:X,:Y])
mean(array(populationData),1)
1x2 Array{Float64,2}:
-0.0281916 -0.022319
cov(array(populationData))
2x2 Array{Float64,2}:
0.98665 0.500912
0.500912 1.00195
In this simulated population, the estimated mean and variance of
 = \Phi\left( \beta_0 + \beta_1 X_i \right)")
where 

beta_0 = 0
beta_1 = 1
index = (beta_0 + beta_1*data[:X])
probability = cdf(Normal(0,1),index)
D = zeros(N)
for i=1:N
D[i] = rand(Bernoulli(probability[i]))
end
populationData[:D] = D
sampleData = populationData
sampleData[D.==0,:Y] = NA
The sample data has missing values in place of 
Correction 2: Inverse Probability Weighting
The reason for the biased estimates of the mean and variance of
In the above simulation, conditional on appearing in the population, the probability that an individual of type 

Before we can make the correct, we must first estimate the probability of sample inclusion. This can be done by fitting the probit regression above by least-squares. For this, we use the GLM package in Julia, which can be installed the usual way with the command Pkg.add(“GLM”).
using GLM
Probit = glm(D ~ X, sampleData, Binomial(), ProbitLink())
DataFrameRegressionModel{GeneralizedLinearModel,Float64}:
Coefficients:
Estimate Std.Error z value Pr(>|z|)
(Intercept) 0.114665 0.148809 0.770554 0.4410
X 1.14826 0.21813 5.26414 1e-6
estProb = predict(Probit)
weights = 1./estProb[D.==1]/sum(1./estProb[D.==1])
which are the inverse probability weights needed to match the sample distribution to the population distribution.
Now, we use the inverse probability weights to correct the mean and variance estimates of
correctedMean = sum(sampleData[D.==1,:Y].*weight) -0.024566923132025013 correctedVariance = (N/(N-1))*sum((sampleData[D.==1,:Y]-correctedMean).^2.*weight) 1.0094029613131092
which are very close to the population values of -0.022319 and 1.00195. The logic here extends to the case of multivariate
Example 3: Generalized Roy Model
For the final example of this tutorial, we consider a model which allows for rich, realistic economic behavior. In words, the Generalized Roy Model is the economic representation of a world in which each individual must choose between two options, where each option has its own benefits, and one of the options costs more than the other. In math notation, the first alternative, denoted
+U_{1,i}")
Similarly, the second alternative, denoted
+U_{0,i}")
The value of
Y_{0,i}")
Finally, the value of 

where 
+U_{C,i}")
where 
We assume that the data only contains 




srand(2) N = 1000 sampleData = DataFrame(rand(MvNormal([0,0.],[1 .5; .5 1]),N)') names!(sampleData,[:X,:Z]) U1 = rand(Normal(0,.5),N) U0 = rand(Normal(0,.7),N) UC = rand(Normal(0,.9),N) betas1 = [0,1] betas0 = [.3,.2] betasC = [.1,.1,.1] Y1 = betas1[1] + betas1[2].*sampleData[:X] + U1 Y0 = betas0[1] + betas0[2].*sampleData[:X] + U0 C = betasC[1] + betasC[2].*sampleData[:X] + betasC[3].*sampleData[:Z] + UC D = Y1-Y0-C.>0 Y = D.*Y1 + (1-D).*Y0 sampleData[:D] = D sampleData[:Y] = Y
In this simulation, about 38% of individuals choose the alternative
Solution 3: Heckman Correction for Generalized Roy Model
The identification of this model is attributable to Heckman and Honore (1990). Estimation proceeds in steps. The first step is to notice that the left- and right-hand terms in the following moment equation motivate a Probit regression:
![\mathbb{E}\left[D_i\Big|X_i,Z_i\right]=\Pr\left(\mu_D\left(X_i,Z_i\right)>U_{D,i}\Big|X_i,Z_i\right)=\Phi\left(\mu_D\left(X_i,Z_i\right)\right)](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BD_i%5CBig%7CX_i%2CZ_i%5Cright%5D%3D%5CPr%5Cleft%28%5Cmu_D%5Cleft%28X_i%2CZ_i%5Cright%29%3EU_%7BD%2Ci%7D%5CBig%7CX_i%2CZ_i%5Cright%29%3D%5CPhi%5Cleft%28%5Cmu_D%5Cleft%28X_i%2CZ_i%5Cright%29%5Cright%29&bg=ffffff&%23038;fg=333333&%23038;s=0 "\mathbb{E}\left[D_i\Big|X_i,Z_i\right]=\Pr\left(\mu_D\left(X_i,Z_i\right)>U_{D,i}\Big|X_i,Z_i\right)=\Phi\left(\mu_D\left(X_i,Z_i\right)\right)")
where /\sigma_D\sim\mathcal{N}\left(0,1\right)")
}")
![\mu_D\left(X,Z\right) \equiv \left([1,X]\beta_1 -[1,X]\beta_0 -[1,X,Z]\beta_C\right)/\sigma_D \equiv [1,X,Z]\beta_D](https://s0.wp.com/latex.php?latex=%5Cmu_D%5Cleft%28X%2CZ%5Cright%29+%5Cequiv+%5Cleft%28%5B1%2CX%5D%5Cbeta_1+-%5B1%2CX%5D%5Cbeta_0+-%5B1%2CX%2CZ%5D%5Cbeta_C%5Cright%29%2F%5Csigma_D+%5Cequiv+%5B1%2CX%2CZ%5D%5Cbeta_D&bg=ffffff&%23038;fg=333333&%23038;s=0 "\mu_D\left(X,Z\right) \equiv \left([1,X]\beta_1 -[1,X]\beta_0 -[1,X,Z]\beta_C\right)/\sigma_D \equiv [1,X,Z]\beta_D")
In the simulation above, ![\beta_D = [-.4,.7,-.1]/\sqrt{.5+.7+.9}\approx[-0.276,0.483,-0.069]](https://s0.wp.com/latex.php?latex=%5Cbeta_D+%3D+%5B-.4%2C.7%2C-.1%5D%2F%5Csqrt%7B.5%2B.7%2B.9%7D%5Capprox%5B-0.276%2C0.483%2C-0.069%5D&bg=ffffff&%23038;fg=333333&%23038;s=0 "\beta_D = [-.4,.7,-.1]/\sqrt{.5+.7+.9}\approx[-0.276,0.483,-0.069]")

betasD = coef(glm(D~X+Z,sampleData,Binomial(),ProbitLink()))
3-element Array{Float64,1}:
-0.299096
0.59392
-0.103155
Next, notice that,
![\mathbb{E}\left[Y_i\Big|D_i=1,X_i,Z_i\right] =[1,X_i]\beta_1+\mathbb{E}\left[U_{1,i}\Big|D_i=1,X_i,Z_i\right]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BY_i%5CBig%7CD_i%3D1%2CX_i%2CZ_i%5Cright%5D+%3D%5B1%2CX_i%5D%5Cbeta_1%2B%5Cmathbb%7BE%7D%5Cleft%5BU_%7B1%2Ci%7D%5CBig%7CD_i%3D1%2CX_i%2CZ_i%5Cright%5D&bg=ffffff&%23038;fg=333333&%23038;s=0 "\mathbb{E}\left[Y_i\Big|D_i=1,X_i,Z_i\right] =[1,X_i]\beta_1+\mathbb{E}\left[U_{1,i}\Big|D_i=1,X_i,Z_i\right]")
where,
![\mathbb{E}\left[U_{1,i}\Big|D_i=1,X_i,Z_i\right] =\mathbb{E}\left[U_{1,i}\Big|\mu_D\left(X_i,Z_i\right)>U_{i,D},X_i,Z_i\right]=\rho_1 \frac{-\phi\left(\mu_D\left(X_i,Z_i\right)\right)}{\Phi\left(\mu_D\left(X_i,Z_i\right)\right)}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BU_%7B1%2Ci%7D%5CBig%7CD_i%3D1%2CX_i%2CZ_i%5Cright%5D+%3D%5Cmathbb%7BE%7D%5Cleft%5BU_%7B1%2Ci%7D%5CBig%7C%5Cmu_D%5Cleft%28X_i%2CZ_i%5Cright%29%3EU_%7Bi%2CD%7D%2CX_i%2CZ_i%5Cright%5D%3D%5Crho_1+%5Cfrac%7B-%5Cphi%5Cleft%28%5Cmu_D%5Cleft%28X_i%2CZ_i%5Cright%29%5Cright%29%7D%7B%5CPhi%5Cleft%28%5Cmu_D%5Cleft%28X_i%2CZ_i%5Cright%29%5Cright%29%7D&bg=ffffff&%23038;fg=333333&%23038;s=0 "\mathbb{E}\left[U_{1,i}\Big|D_i=1,X_i,Z_i\right] =\mathbb{E}\left[U_{1,i}\Big|\mu_D\left(X_i,Z_i\right)>U_{i,D},X_i,Z_i\right]=\rho_1 \frac{-\phi\left(\mu_D\left(X_i,Z_i\right)\right)}{\Phi\left(\mu_D\left(X_i,Z_i\right)\right)}")
which is the inverse Mills ratio again, where }{\mathrm{Var}\left(U_D\right)}")
fittedVals = hcat(ones(N),array(sampleData[[:X,:Z]]))*betasD
sampleData[:invMills1] = -pdf(Normal(0,1),fittedVals)./cdf(Normal(0,1),fittedVals)
correctedBetas1 = linreg(array(sampleData[D,[:X,:invMills1]]),vec(array(sampleData[D,[:Y]])))
3-element Array{Float64,1}:
0.0653299
0.973568
-0.135445
To see how well the correction has performed, compare these estimates to the uncorrected estimates of
biasedBetas1 = linreg(array(sampleData[D,[:X]]),vec(array(sampleData[D,[:Y]])))
2-element Array{Float64,1}:
0.202169
0.927317
Similar logic allows us to estimate
sampleData[:invMills0] = pdf(Normal(0,1),fittedVals)./(1-cdf(Normal(0,1),fittedVals))
correctedBetas0 = linreg(array(sampleData[D.==0,[:X,:invMills0]]),vec(array(sampleData[D.==0,[:Y]])))
3-element Array{Float64,1}:
0.340621
0.207068
0.323793
biasedBetas0 = linreg(array(sampleData[D.==0,[:X]]),vec(array(sampleData[D.==0,[:Y]])))
2-element Array{Float64,1}:
0.548451
0.295698
In summary, we can consistently estimate the benefits associated with each of two alternative choices, even though we only observe each individual in one of the alternatives, subject to heavy selection bias, by extending the logic introduced by Heckman (1979).
Bradley J. Setzler
 = \gamma (1-\tau) w_i + \gamma \epsilon_i")
 = (1-\gamma) + \frac{(1-\gamma) \epsilon_i}{ (1-\tau) w_i}")
![\hat{m}\left(\gamma,\tau\right)=\mathbb{E}_{\epsilon}\left[\begin{array}{c} \frac{1}{N}\sum_{i}\left[\hat{c}_{i}\left(\epsilon\right)-c_{i}\right]\\ \frac{1}{N}\sum_{i}\left[\hat{l}_{i}\left(\epsilon\right)-l_{i}\right] \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Chat%7Bm%7D%5Cleft%28%5Cgamma%2C%5Ctau%5Cright%29%3D%5Cmathbb%7BE%7D_%7B%5Cepsilon%7D%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D+%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bi%7D%5Cleft%5B%5Chat%7Bc%7D_%7Bi%7D%5Cleft%28%5Cepsilon%5Cright%29-c_%7Bi%7D%5Cright%5D%5C%5C+%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bi%7D%5Cleft%5B%5Chat%7Bl%7D_%7Bi%7D%5Cleft%28%5Cepsilon%5Cright%29-l_%7Bi%7D%5Cright%5D+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&%23038;fg=333333&%23038;s=0 "\hat{m}\left(\gamma,\tau\right)=\mathbb{E}_{\epsilon}\left[\begin{array}{c} \frac{1}{N}\sum_{i}\left[\hat{c}_{i}\left(\epsilon\right)-c_{i}\right]\\ \frac{1}{N}\sum_{i}\left[\hat{l}_{i}\left(\epsilon\right)-l_{i}\right] \end{array}\right]")
![\left(\hat{\gamma},\hat{\tau}\right)=\arg\min_{\gamma\in\left[0,1\right],\tau\in\left[0,1\right]}\hat{m}\left(\gamma,\tau\right)'W\hat{m}\left(\gamma,\tau\right)](https://s0.wp.com/latex.php?latex=%5Cleft%28%5Chat%7B%5Cgamma%7D%2C%5Chat%7B%5Ctau%7D%5Cright%29%3D%5Carg%5Cmin_%7B%5Cgamma%5Cin%5Cleft%5B0%2C1%5Cright%5D%2C%5Ctau%5Cin%5Cleft%5B0%2C1%5Cright%5D%7D%5Chat%7Bm%7D%5Cleft%28%5Cgamma%2C%5Ctau%5Cright%29%27W%5Chat%7Bm%7D%5Cleft%28%5Cgamma%2C%5Ctau%5Cright%29&bg=ffffff&%23038;fg=333333&%23038;s=0 "\left(\hat{\gamma},\hat{\tau}\right)=\arg\min_{\gamma\in\left[0,1\right],\tau\in\left[0,1\right]}\hat{m}\left(\gamma,\tau\right)'W\hat{m}\left(\gamma,\tau\right)")
![\left(\hat{\gamma},\hat{\tau}\right)=\arg\min_{\gamma\in\left[0,1\right],\tau\in\left[0,1\right]}\left\{ \mathbb{E}_{\epsilon}\left[\frac{1}{N}\sum_{i}\left[\hat{c}_{i}\left(\epsilon\right)-c_{i}\right]\right]\right\} ^{2}+\left\{ \mathbb{E}_{\epsilon}\left[\frac{1}{N}\sum_{i}\left[\hat{l}_{i}\left(\epsilon\right)-l_{i}\right]\right]\right\} ^{2}](https://s0.wp.com/latex.php?latex=%5Cleft%28%5Chat%7B%5Cgamma%7D%2C%5Chat%7B%5Ctau%7D%5Cright%29%3D%5Carg%5Cmin_%7B%5Cgamma%5Cin%5Cleft%5B0%2C1%5Cright%5D%2C%5Ctau%5Cin%5Cleft%5B0%2C1%5Cright%5D%7D%5Cleft%5C%7B+%5Cmathbb%7BE%7D_%7B%5Cepsilon%7D%5Cleft%5B%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bi%7D%5Cleft%5B%5Chat%7Bc%7D_%7Bi%7D%5Cleft%28%5Cepsilon%5Cright%29-c_%7Bi%7D%5Cright%5D%5Cright%5D%5Cright%5C%7D+%5E%7B2%7D%2B%5Cleft%5C%7B+%5Cmathbb%7BE%7D_%7B%5Cepsilon%7D%5Cleft%5B%5Cfrac%7B1%7D%7BN%7D%5Csum_%7Bi%7D%5Cleft%5B%5Chat%7Bl%7D_%7Bi%7D%5Cleft%28%5Cepsilon%5Cright%29-l_%7Bi%7D%5Cright%5D%5Cright%5D%5Cright%5C%7D+%5E%7B2%7D&bg=ffffff&%23038;fg=333333&%23038;s=0 "\left(\hat{\gamma},\hat{\tau}\right)=\arg\min_{\gamma\in\left[0,1\right],\tau\in\left[0,1\right]}\left\{ \mathbb{E}_{\epsilon}\left[\frac{1}{N}\sum_{i}\left[\hat{c}_{i}\left(\epsilon\right)-c_{i}\right]\right]\right\} ^{2}+\left\{ \mathbb{E}_{\epsilon}\left[\frac{1}{N}\sum_{i}\left[\hat{l}_{i}\left(\epsilon\right)-l_{i}\right]\right]\right\} ^{2}")
![\mathbb{E}\left[Y_i\Big|X_i,i\in\mathcal{S}\right]=\beta_0 + \beta_1X_i+\frac{-\phi\left(X_i\right)}{\Phi\left(X_i\right)}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5BY_i%5CBig%7CX_i%2Ci%5Cin%5Cmathcal%7BS%7D%5Cright%5D%3D%5Cbeta_0+%2B+%5Cbeta_1X_i%2B%5Cfrac%7B-%5Cphi%5Cleft%28X_i%5Cright%29%7D%7B%5CPhi%5Cleft%28X_i%5Cright%29%7D&bg=ffffff&%23038;fg=333333&%23038;s=0 "\mathbb{E}\left[Y_i\Big|X_i,i\in\mathcal{S}\right]=\beta_0 + \beta_1X_i+\frac{-\phi\left(X_i\right)}{\Phi\left(X_i\right)}")