By: Jacob Quinn
Re-posted from: https://quinnj.home.blog/2019/08/24/everyones-favorite-blogpost-csv-benchmarks/
We all know ’em, we all hate ’em, let’s get a good benchmarking blogpost up in here. Most people who groggily glance at their phone at 5:30 AM just roll over and go back to sleep. For some of us, you also open up the email just to see if there’s anything interesting really quick. And for the very small minority out there, we have a “performance issue” opened on one of our precious darling open-source libraries and THAT’S IT! no more sleep until this internet stranger can be proven wrong! (for the record, the issue in question is here and xiaodiagh isn’t an internet stranger, but a great buddy I got to meet at JuliaCon 2019 in Baltimore this year who is doing some really cool work on grouping performance in Julia; but you know, “internet stranger” is a lot funnier).
Some of you may heard/seen that multithreaded csv parsing support recently landed in CSV.jl, my aforementioned precious darling. So naturally, it’s a good time to round up some benchmarks and show how competitive we are in the csv parsing landscape. I apologize for the lack of fancy graphics and pretty charts, but I’m more interested in the numbers; pretty chart PRs welcome to CSV.jl!
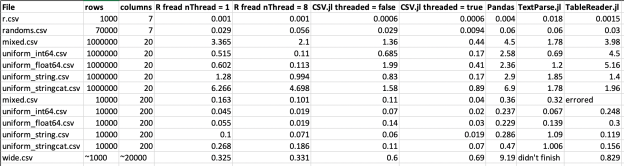
Hey! Look at that! CSV.jl is basically on par with R’s fread!
Now, I’ll add my personal opinion on these kind of benchmark comparisons: always take them with a grain of salt. Benchmarking tends to rely on contrived data that can sometimes be biased one way or another; it can be system dependent in a bunch of ways, they are only accurate for a given amount of time while packages continue to develop/decay, caveat, caveat, caveat. BUT, they also tend to be directionally accurate, and that’s what I’m most pleased with here, particularly with regards to fread‘s one remaining advantage over CSV.jl in terms of multithreading support. (For full feature comparison between CSV.jl, fread, and pandas, see the CSV.jl 0.5 release announcement).
The files + benchmark script can be found here; the single-typed files and mixed.csv are derived from this benchmark site. The benchmark numbers shown above were run on my system: 2019 MacBook Pro, 2.4 GHz Intel Core i9, 32 GB 2400 MHz DDR4 RAM. The benchmarks were run using CSV.jl#master branch, as the last few things get ironed out before a release which will include multithreading support for Julia versions 1.3+.
As always, hit me up on Twitter to chat or follow my #JuliaLang tweets.